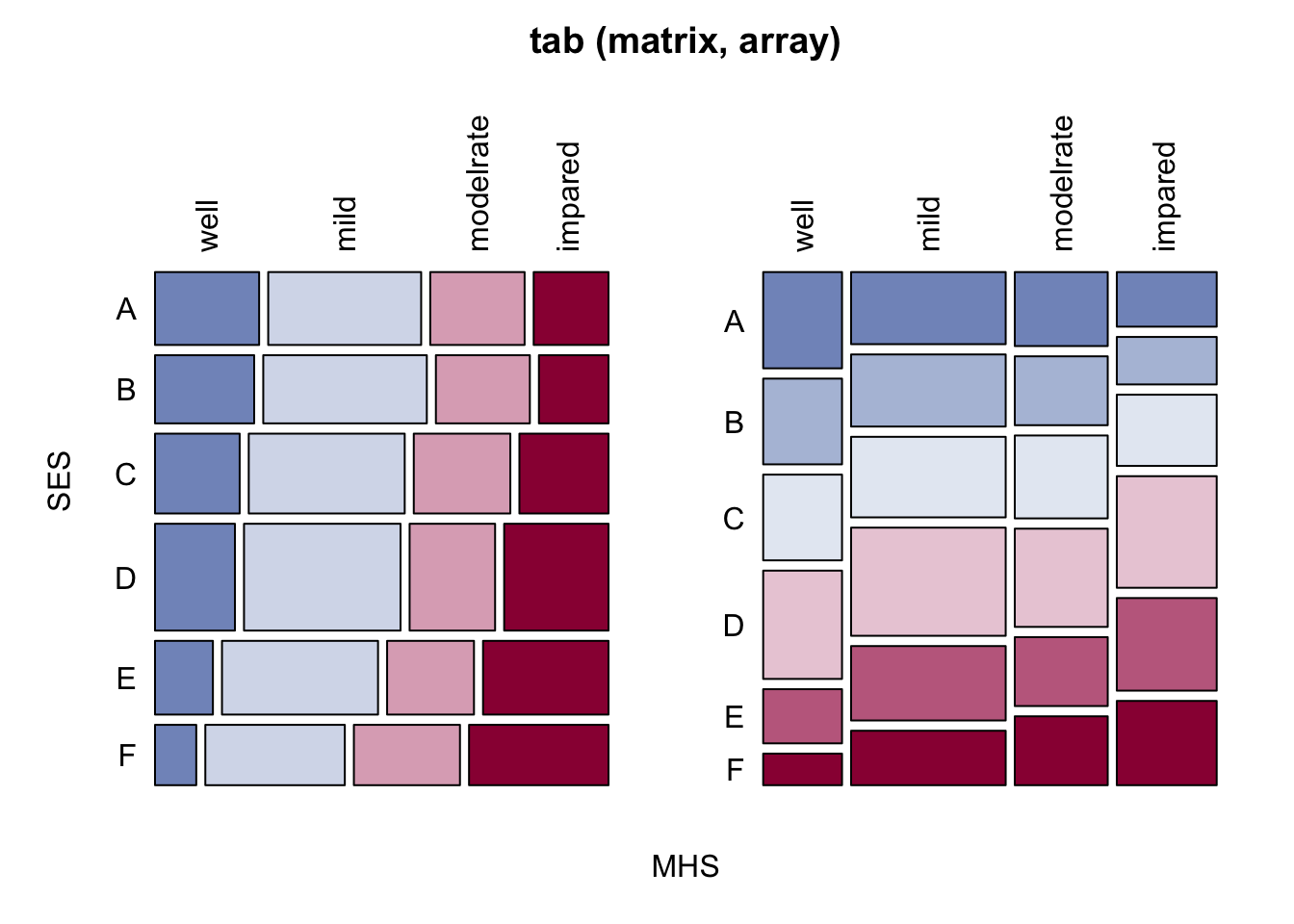
# 第1章 - 本章ですこし触れられてる連関の尺度のいくつかは`DescTools` パッケージの`Assocs` で求めることができる.- 「シリーズ編者による内容紹介」の精神的健康と親の社会経済的地位(SES)に関するミッドタウン・マンハッタンデータ(the Midtown Manhattan data)を用いて分析する.```{r} # 元データの入力(xページ) <- c ( 64 , 94 , 58 , 46 ,57 , 94 , 54 , 40 ,57 , 105 , 65 , 60 ,72 , 141 , 77 , 94 ,36 , 97 , 54 , 78 ,21 , 71 , 54 , 71 )# データを表形式に変換 <- matrix (nrow = 6 ,ncol = 4 ,byrow = TRUE ,dimnames = list (SES = LETTERS[1 : 6 ],MHS = c ("well" ,"mild" ,"moderate" ,"impaired" )``` `DescTools` パッケージを用いる.```{r} library (DescTools):: Desc (tab):: Assocs (tab)``` `?DescTools` の`Statistics:` を確認してほしい.```{r} :: CramerV (tab, conf.level = 0.95 ):: Lambda (tab, conf.level = 0.95 ):: GoodmanKruskalTau (tab, conf.level = 0.95 ):: KendallTauB (tab, conf.level = 0.95 ):: StuartTauC (tab, conf.level = 0.95 ):: GoodmanKruskalGamma (tab, conf.level = 0.95 ):: SomersDelta (tab, conf.level = 0.95 ):: UncertCoef (tab, conf.level = 0.95 )``` ## クラメールのV `chisq.test(tab)$statistic` でカイ2乗値を取り出すことができるが,`unname` 関数で取り除く.`as.numeric` としても取り除くことができる.```{r} <- chisq.test (tab)$ statistic |> unname () # あるいはas.numeric() <- sqrt (X2/ sum (tab)/ (min (dim (tab)) - 1 ))``` `tab` の2行目を10倍,1列目を10倍したデータを考える.これを`tab10` とする.```{r} <- tab1 ] <- tab10[,1 ]* 10 2 ,] <- tab10[2 ,]* 10 ``` ```{r} :: CramerV (tab):: CramerV (tab10):: GoodmanKruskalTau (tab):: GoodmanKruskalTau (tab10):: KendallTauB (tab):: KendallTauB (tab10):: StuartTauC (tab):: StuartTauC (tab10):: GoodmanKruskalGamma (tab):: GoodmanKruskalGamma (tab10):: SomersDelta (tab):: SomersDelta (tab10):: UncertCoef (tab):: UncertCoef (tab10)``` ```{r} # 2つの表をマージしたデータも作成 <- dplyr:: bind_rows (data.frame (as.table (tab)),data.frame (as.table (tab10)),.id = "Tab" ) |> xtabs (Freq ~ SES + MHS + Tab, data = _)# intrinsic association coefficient :: iac (tab, weighting = "none" ):: iac (tab10, weighting = "none" ):: iac (tab_merge, weighting = "none" )# Altham index :: iac (tab, weighting = "none" ) * sqrt (nrow (tab) * ncol (tab)) * 2 :: iac (tab10, weighting = "none" ) * sqrt (nrow (tab) * ncol (tab)) * 2 :: iac (tab_merge, weighting = "none" ) * sqrt (nrow (tab) * ncol (tab)) * 2 # Shrinkage Estimation :: iac (tab_merge, weighting = "none" , shrink= TRUE ) * sqrt (nrow (tab_merge) * ncol (tab_merge)) * 2 * 2 # Mean absolute odds ratio :: maor (tab, weighting = "uniform" ):: maor (tab10, weighting = "uniform" ):: maor (tab_merge, weighting = "uniform" )``` ```{r} # intrinsic association coefficient :: iac (tab, weighting = "marginal" ):: iac (tab10, weighting = "marginal" )# Mean absolute odds ratio :: maor (tab, weighting = "marginal" ):: maor (tab10, weighting = "marginal" )``` ## 練習問題 {-} `occupationalStatus` はRの組み込みデータセットで、イギリス男性の父親(origin)と息子(destination)の職業地位(8段階)をクロス表にしたものである。- 出典: @goodman1979a Table 3.```{r} ``` ## 参考文献 {-}