library(tidyverse)
library(broom)
library(gnm)
library(vcd)
library(DescTools)
library(logmult)
library(knitr)2 第2章
第2章では2元表の連関モデルが紹介されている.制約のかけかたは少し複雑なのでプログラムとテキストをみながら手順を確認して欲しい.
パッケージはtidyverse(データセットの処理のため),DescTools(記述統計を求めるため),vcdパッケージ(カテゴリカルデータの分析のため),broom(回帰係数の整理),gnm(連関分析の処理のため),logmult(連関モデルのため)を使用する.
2.1 対比について
回帰モデルにおけるカテゴリカル変数の係数を解釈する上では対比 (contrasts)が重要である.まずはモデルを推定できるようになることのほうが重要なので, ひとまずとばして次の Section 2.2 から読みすすめてもよい.
まず,デフォルト(標準の状態)でのcontrastsを確認したい.factor変数についてはcontr.treatment,ordered変数についてはcontr.polyという対比が用いられている.contr.treatmentは基準となっている水準とそれぞれの水準を対比する.これはダミーコーディングと呼ばれる. contr.polyは直交多項式(orthogonal polynomials)に基づいた対比を行う(気にしなくてよい).
# デフォルトのcontrastsを確認
options("contrasts")$contrasts
unordered ordered
"contr.treatment" "contr.poly" # defaultのcontrastsの設定(ここでは特に意味はない.constrastをいじった後にデフォルトに戻す)
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))具体的に何をしているのかを以下のプログラムで確認する. ダミーコーディングのcontr.treatment以外にも効果コーディングのcontr.sumがある.まずは両者を比較してみたい.
# データの作成
x <- c("A","B","C","D","E")
# 確認
x[1] "A" "B" "C" "D" "E"# 基準カテゴリが0となるような対比
contr.treatment(x) B C D E
A 0 0 0 0
B 1 0 0 0
C 0 1 0 0
D 0 0 1 0
E 0 0 0 1# 合計が0となるような対比
contr.sum(x) [,1] [,2] [,3] [,4]
A 1 0 0 0
B 0 1 0 0
C 0 0 1 0
D 0 0 0 1
E -1 -1 -1 -1実際に回帰分析を例にcontr.treatmentとcontr.sumの違いを確認する.データはforcatsパッケージ(tidyverseに含まれる)のgss_cat(A sample of categorical variables from the General Social survey)である.従属変数はtvhours(hours per day watching tv)であり,独立変数はmarital(marital status)とする.
# class別のtvhoursの平均値
gss_cat |>
dplyr::summarise(n = sum(!is.na(tvhours)),
Mean = mean(tvhours, na.rm = TRUE),
.by = marital) |>
mutate(Diff_1 = Mean - Mean[marital == "Never married"],
Diff_2 = Mean - mean(Mean))# A tibble: 6 × 5
marital n Mean Diff_1 Diff_2
<fct> <int> <dbl> <dbl> <dbl>
1 Never married 2995 3.11 0 -0.0379
2 Divorced 1768 3.09 -0.0198 -0.0576
3 Widowed 1000 3.91 0.807 0.769
4 Married 5172 2.65 -0.455 -0.493
5 Separated 393 3.55 0.444 0.407
6 No answer 9 2.56 -0.550 -0.587 水準はlevels関数で確認できる.1つ目の水準はNo answerであり,最後の水準はMarriedである.
# 水準の確認
gss_cat$marital |> levels()[1] "No answer" "Never married" "Separated" "Divorced"
[5] "Widowed" "Married" まずダミーコーディング(dummy coding)の結果を確認する.
# 回帰分析の例(contr.treatmentを使用)
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))
# 回帰分析
fit_ct <- lm(tvhours ~ marital, data = gss_cat)
# 回帰分析の結果
summary(fit_ct)
Call:
lm(formula = tvhours ~ marital, data = gss_cat)
Residuals:
Min 1Q Median 3Q Max
-3.9120 -1.6504 -0.6504 0.8948 21.3496
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.55556 0.85328 2.995 0.00275 **
maritalNever married 0.54962 0.85456 0.643 0.52013
maritalSeparated 0.99406 0.86300 1.152 0.24940
maritalDivorced 0.52985 0.85545 0.619 0.53568
maritalWidowed 1.35644 0.85711 1.583 0.11355
maritalMarried 0.09487 0.85402 0.111 0.91155
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.56 on 11331 degrees of freedom
(10146 observations deleted due to missingness)
Multiple R-squared: 0.02143, Adjusted R-squared: 0.021
F-statistic: 49.63 on 5 and 11331 DF, p-value: < 2.2e-16# 回帰分析の係数をtidyで表示
tidy(fit_ct, conf.int = TRUE)# A tibble: 6 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.56 0.853 2.99 0.00275 0.883 4.23
2 maritalNever married 0.550 0.855 0.643 0.520 -1.13 2.22
3 maritalSeparated 0.994 0.863 1.15 0.249 -0.698 2.69
4 maritalDivorced 0.530 0.855 0.619 0.536 -1.15 2.21
5 maritalWidowed 1.36 0.857 1.58 0.114 -0.324 3.04
6 maritalMarried 0.0949 0.854 0.111 0.912 -1.58 1.77# モデルマトリックス
model.matrix(fit_ct) |> unique() (Intercept) maritalNever married maritalSeparated maritalDivorced
1 1 1 0 0
3 1 0 0 0
5 1 0 0 1
9 1 0 0 0
88 1 0 1 0
1546 1 0 0 0
maritalWidowed maritalMarried
1 0 0
3 1 0
5 0 0
9 0 1
88 0 0
1546 0 0出力される係数は5つである.maritalはfactorによって水準が設定されているわけではないので,No answerが基準カテゴリとなっており,出力からは省略されている.つまり,No answerの係数は0であり,(Intercept)の値はNo answerの平均値を示している.
次に効果コーディングの結果を確認する.
# 回帰分析の例(contr.sumを使用)
options(contrasts = c(factor = "contr.sum",
ordered = "contr.poly"))
# 回帰分析
fit_cs <- lm(tvhours ~ marital, data = gss_cat)
# 回帰分析の結果
summary(fit_cs)
Call:
lm(formula = tvhours ~ marital, data = gss_cat)
Residuals:
Min 1Q Median 3Q Max
-3.9120 -1.6504 -0.6504 0.8948 21.3496
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.14303 0.14515 21.654 < 2e-16 ***
marital1 -0.58747 0.71166 -0.825 0.4091
marital2 -0.03786 0.15009 -0.252 0.8009
marital3 0.40659 0.17940 2.266 0.0234 *
marital4 -0.05762 0.15343 -0.376 0.7072
marital5 0.76897 0.15949 4.821 1.44e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.56 on 11331 degrees of freedom
(10146 observations deleted due to missingness)
Multiple R-squared: 0.02143, Adjusted R-squared: 0.021
F-statistic: 49.63 on 5 and 11331 DF, p-value: < 2.2e-16# 回帰分析の係数をtidyで表示
tidy(fit_cs, conf.int = TRUE)# A tibble: 6 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.14 0.145 21.7 6.45e-102 2.86 3.43
2 marital1 -0.587 0.712 -0.825 4.09e- 1 -1.98 0.808
3 marital2 -0.0379 0.150 -0.252 8.01e- 1 -0.332 0.256
4 marital3 0.407 0.179 2.27 2.34e- 2 0.0549 0.758
5 marital4 -0.0576 0.153 -0.376 7.07e- 1 -0.358 0.243
6 marital5 0.769 0.159 4.82 1.44e- 6 0.456 1.08 # モデルマトリックス
model.matrix(fit_cs) |> unique() (Intercept) marital1 marital2 marital3 marital4 marital5
1 1 0 1 0 0 0
3 1 0 0 0 0 1
5 1 0 0 0 1 0
9 1 -1 -1 -1 -1 -1
88 1 0 0 1 0 0
1546 1 1 0 0 0 0ここでも出力される係数は5つであるが,ここでは最後のカテゴリであるMarriedが省略されている.しかし,最後のカテゴリであるMarriedの係数は0ではない.すべての係数の和が0になるという制約を与えているので,Marriedの係数は他の係数の値の和を0から引いたものとなる.
# classという文字が含まれる係数を取り出し,係数の番号を調べる(2から6)
pickCoef(fit_cs, "marital")marital1 marital2 marital3 marital4 marital5
2 3 4 5 6 # 係数の2から6までを取り出し,その和を求める.
fit_cs$coefficients[2:6] |> sum()[1] 0.4926049# 直接次のようにしても良い.
fit_cs$coefficients[pickCoef(fit_cs, "marital")] |> sum()[1] 0.4926049# 和を0から引く
0 - (fit_cs$coefficients[2:6] |> sum())[1] -0.4926049したがって,Marriedの係数は-0.4926049となる.
contrastsの設定を変更して分析を終えたら必ずもとに戻しておく.
# デフォルトに戻す
options(contrasts = c(factor = "contr.treatment", ordered = "contr.poly"))
# contrastsを確認
options("contrasts")$contrasts
factor ordered
"contr.treatment" "contr.poly" lmではモデルの中でcontrastsを指定することもできる.2つの方法で係数を比較してみる.
# 回帰分析
fit_cs2_1 <- lm(tvhours ~ marital, data = gss_cat)
# 回帰分析の結果
summary(fit_cs2_1)
Call:
lm(formula = tvhours ~ marital, data = gss_cat)
Residuals:
Min 1Q Median 3Q Max
-3.9120 -1.6504 -0.6504 0.8948 21.3496
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.55556 0.85328 2.995 0.00275 **
maritalNever married 0.54962 0.85456 0.643 0.52013
maritalSeparated 0.99406 0.86300 1.152 0.24940
maritalDivorced 0.52985 0.85545 0.619 0.53568
maritalWidowed 1.35644 0.85711 1.583 0.11355
maritalMarried 0.09487 0.85402 0.111 0.91155
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.56 on 11331 degrees of freedom
(10146 observations deleted due to missingness)
Multiple R-squared: 0.02143, Adjusted R-squared: 0.021
F-statistic: 49.63 on 5 and 11331 DF, p-value: < 2.2e-16# 回帰分析の係数をtidyで表示
tidy(fit_cs2_1, conf.int = TRUE)# A tibble: 6 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.56 0.853 2.99 0.00275 0.883 4.23
2 maritalNever married 0.550 0.855 0.643 0.520 -1.13 2.22
3 maritalSeparated 0.994 0.863 1.15 0.249 -0.698 2.69
4 maritalDivorced 0.530 0.855 0.619 0.536 -1.15 2.21
5 maritalWidowed 1.36 0.857 1.58 0.114 -0.324 3.04
6 maritalMarried 0.0949 0.854 0.111 0.912 -1.58 1.77# 回帰分析
fit_cs2_2 <- lm(tvhours ~ marital, data = gss_cat,
contrasts = list(marital = "contr.sum"))
# 回帰分析の結果
summary(fit_cs2_2)
Call:
lm(formula = tvhours ~ marital, data = gss_cat, contrasts = list(marital = "contr.sum"))
Residuals:
Min 1Q Median 3Q Max
-3.9120 -1.6504 -0.6504 0.8948 21.3496
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.14303 0.14515 21.654 < 2e-16 ***
marital1 -0.58747 0.71166 -0.825 0.4091
marital2 -0.03786 0.15009 -0.252 0.8009
marital3 0.40659 0.17940 2.266 0.0234 *
marital4 -0.05762 0.15343 -0.376 0.7072
marital5 0.76897 0.15949 4.821 1.44e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.56 on 11331 degrees of freedom
(10146 observations deleted due to missingness)
Multiple R-squared: 0.02143, Adjusted R-squared: 0.021
F-statistic: 49.63 on 5 and 11331 DF, p-value: < 2.2e-16# 回帰分析の係数をtidyで表示
tidy(fit_cs2_2)# A tibble: 6 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.14 0.145 21.7 6.45e-102
2 marital1 -0.587 0.712 -0.825 4.09e- 1
3 marital2 -0.0379 0.150 -0.252 8.01e- 1
4 marital3 0.407 0.179 2.27 2.34e- 2
5 marital4 -0.0576 0.153 -0.376 7.07e- 1
6 marital5 0.769 0.159 4.82 1.44e- 6では結果を図にしてみる.
# termのカテゴリ名を変換し,最後に`No answer`の行を加える.
est_ct <- fit_ct |>
tidy(conf.int = TRUE) |> # 回帰分析の係数をtidyで表示し,信頼区間もつける
mutate(term = case_when(
grepl("Never", term) ~ "Never married",
grepl("Separated", term) ~ "Separated",
grepl("Divorced", term) ~ "Divorced",
grepl("Widowed", term) ~ "Widowed",
grepl("Married", term) ~ "Married",
.default = term
)) |>
add_row(term = "No answer", estimate = 0)
est_ct# A tibble: 7 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.56 0.853 2.99 0.00275 0.883 4.23
2 Never married 0.550 0.855 0.643 0.520 -1.13 2.22
3 Separated 0.994 0.863 1.15 0.249 -0.698 2.69
4 Divorced 0.530 0.855 0.619 0.536 -1.15 2.21
5 Widowed 1.36 0.857 1.58 0.114 -0.324 3.04
6 Married 0.0949 0.854 0.111 0.912 -1.58 1.77
7 No answer 0 NA NA NA NA NA # 結果を図示する.
fig_ct <- est_ct |>
ggplot(aes(x = term,
y = estimate,
ymin = conf.low,
ymax = conf.high)) +
geom_pointrange() +
theme_minimal()
fig_ct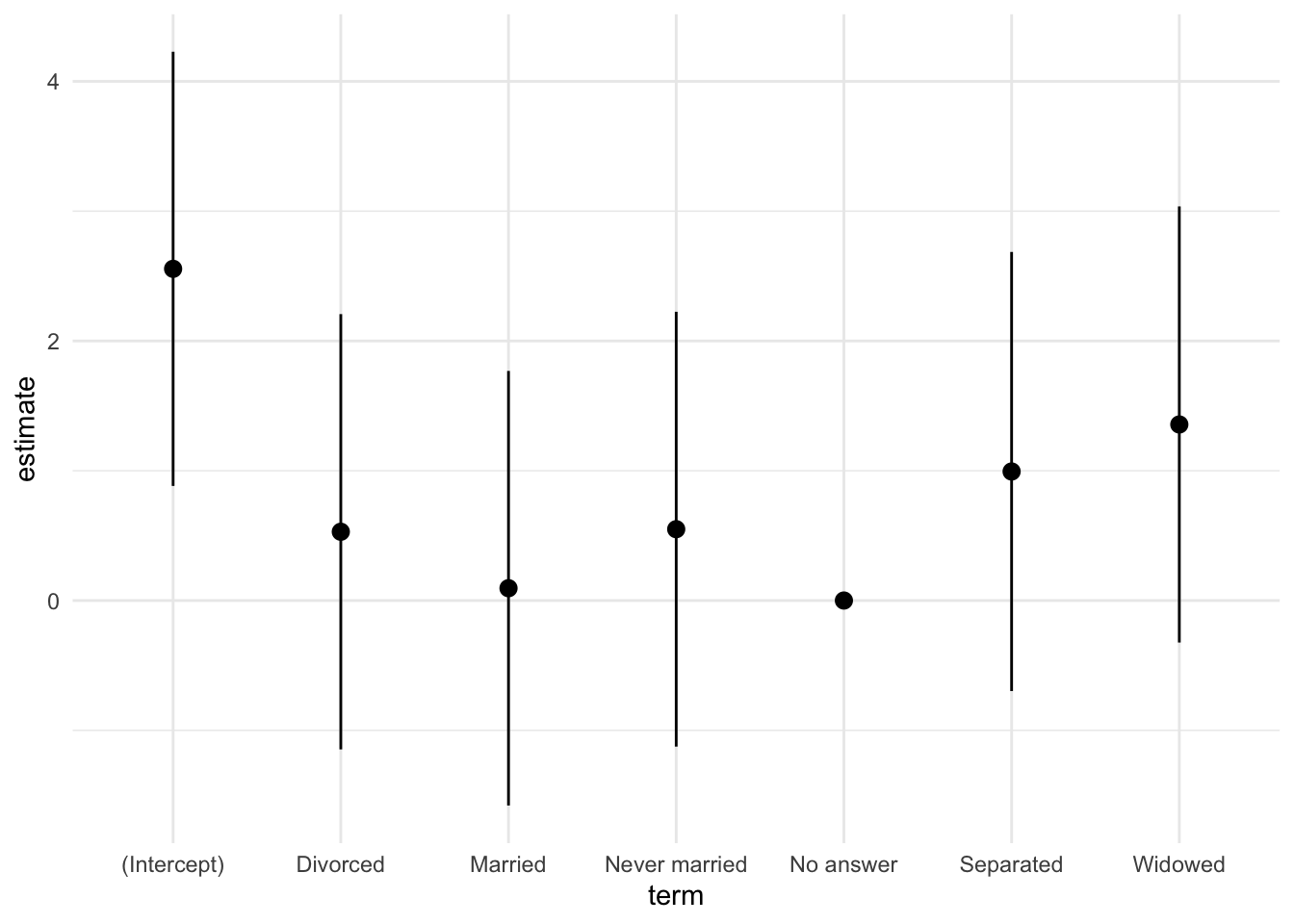
# termのカテゴリ名を変換し,最後に`Married`の行を加える.
est_cs <- fit_cs |>
tidy(conf.int = TRUE) |>
mutate(term = case_match(term,
"marital1" ~ "No answer",
"marital2" ~ "Never married",
"marital3" ~ "Separated",
"marital4" ~ "Divorced",
"marital5" ~ "Widowed",
"marital6" ~ "Married",
.default = term)) |>
add_row(term = "Married",
estimate = 0 - (fit_cs$coefficients[2:6] |> sum()))
# 結果を図示する.
fit_cs <- est_cs |>
ggplot(aes(x = term,
y = estimate,
ymin = conf.low,
ymax = conf.high)) +
geom_pointrange() +
theme_minimal()
fit_cs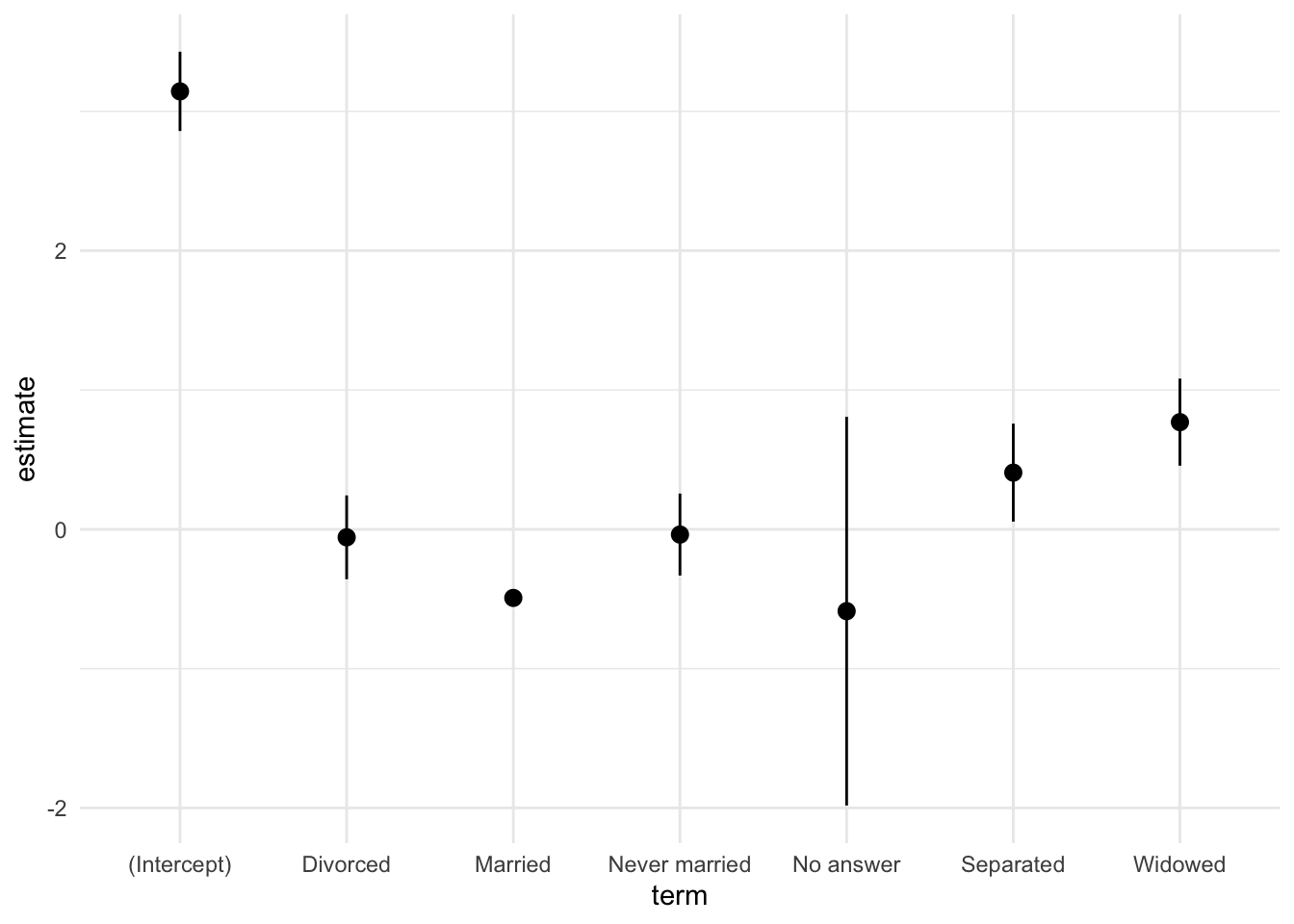
# 図を並べる
ggpubr::ggarrange(fig_ct, fit_cs, nrow = 2)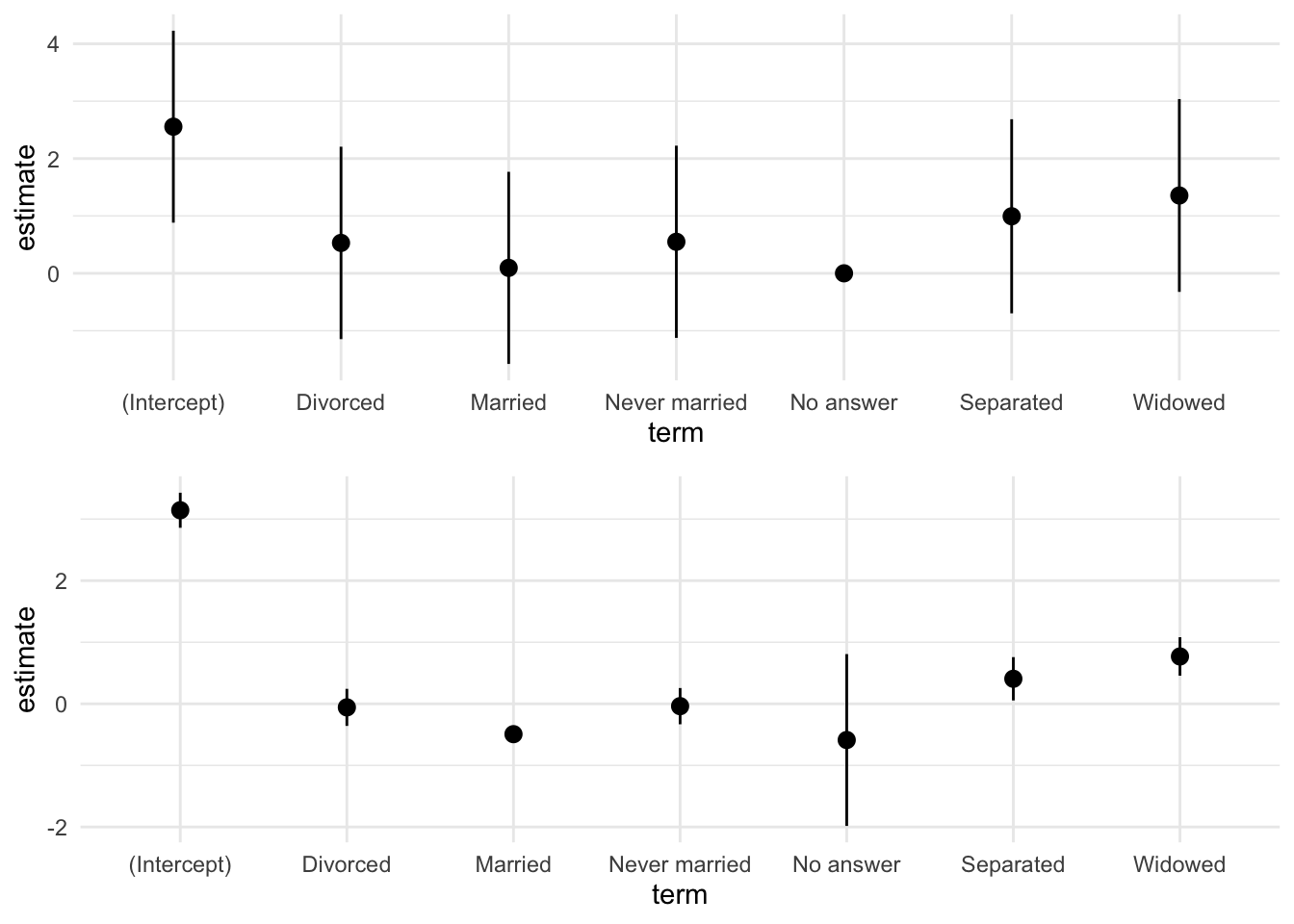
2.2 表2.1 (p.11)
まずp.11の表2.1を再現する.クロス表に周辺度数を追加する場合は,addmarginsを用いる.
# 度数
Freq <- c( 40, 250,
160,3000)
Freq[1] 40 250 160 3000ベクトルを表にする.ここではas.tableでクラスをtableとしている.
# 行列を作成し,表とする.
tab_2.1 <- matrix(
Freq,
nrow = 2,
ncol = 2,
byrow = TRUE,
dimnames = c(list(
Member = c("Member", "Nonmember"),
Position = c("Have subordinates",
"No subordinates")
))
) |> as.table()
tab_2.1 Position
Member Have subordinates No subordinates
Member 40 250
Nonmember 160 3000周辺分布とモザイクプロットも確認する.本書で指摘されている関係性が図からも見て取れる.
# 周辺分布の表示
Margins(tab_2.1)$Member
level freq perc cumfreq cumperc
1 Member 290 8.4% 290 8.4%
2 Nonmember 3'160 91.6% 3'450 100.0%
$Position
level freq perc cumfreq cumperc
1 Have subordinates 200 5.8% 200 5.8%
2 No subordinates 3'250 94.2% 3'450 100.0%# モザイクプロット
vcd::mosaic(tab_2.1, shade = TRUE, keep_aspect_ratio = FALSE)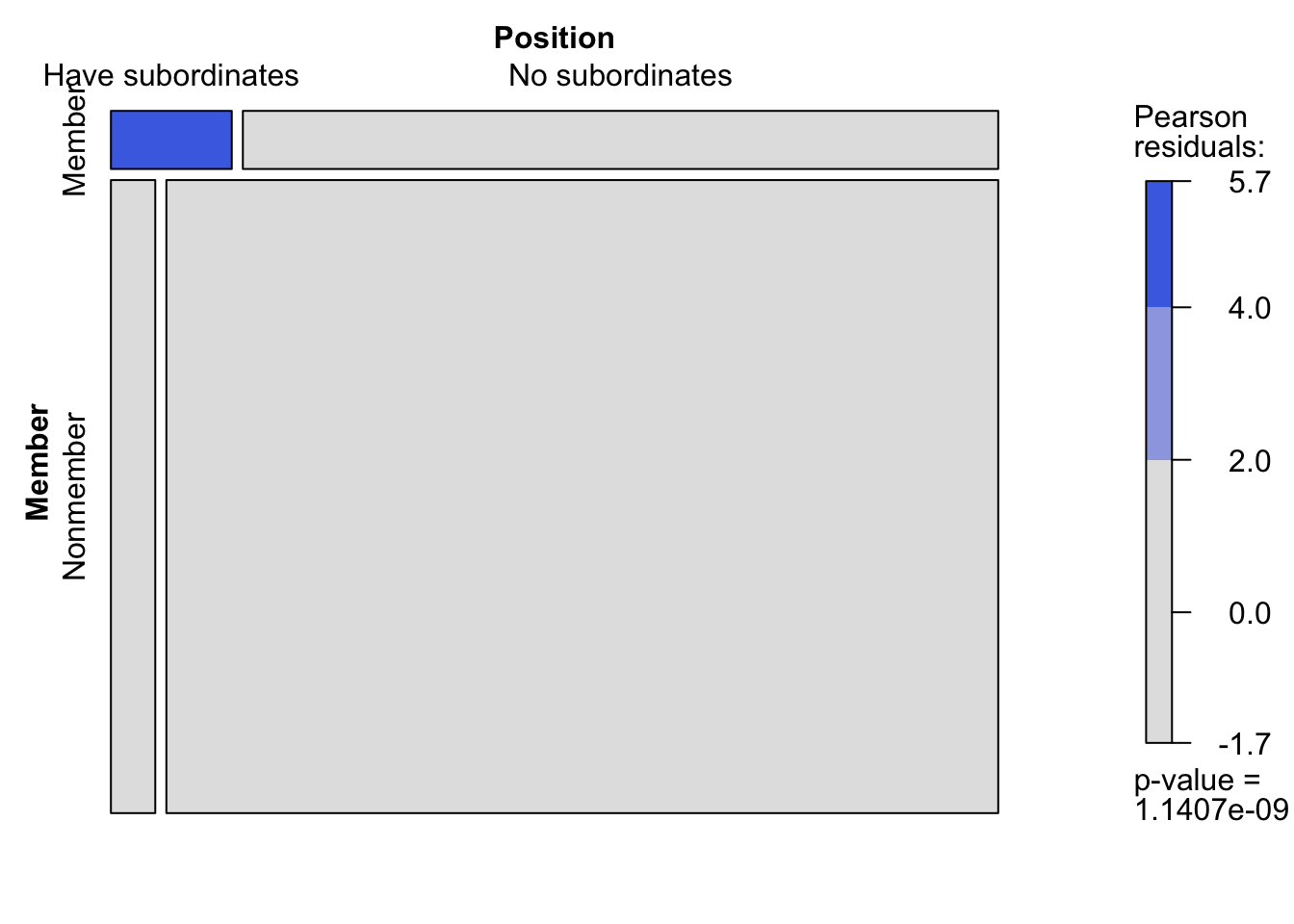
ggplotでモザイクプロット
図はすべてggplot()を使用して描きたいという場合は,ggmosaicパッケージを用いる. その前に集計データをvcdExtra::expand.dft()によって個票データに変換し,ggmosaic::geom_mosaicを使用する.
# パッケージの呼び出し
library(ggmosaic)
library(vcdExtra)
# データの変換
df_tab_2.1 <- vcdExtra::expand.dft(data.frame(tab_2.1), dreq = "Freq") |> tibble()
df_tab_2.1# A tibble: 3,450 × 2
Member Position
<chr> <chr>
1 Member Have subordinates
2 Member Have subordinates
3 Member Have subordinates
4 Member Have subordinates
5 Member Have subordinates
6 Member Have subordinates
7 Member Have subordinates
8 Member Have subordinates
9 Member Have subordinates
10 Member Have subordinates
# ℹ 3,440 more rows# ggplotでモザイクプロット
df_tab_2.1 |>
ggplot() +
ggmosaic::geom_mosaic(aes(x = product(Position, Member), fill = Position)) +
scale_fill_viridis_d() +
coord_flip() # mosaicと表示をあわせる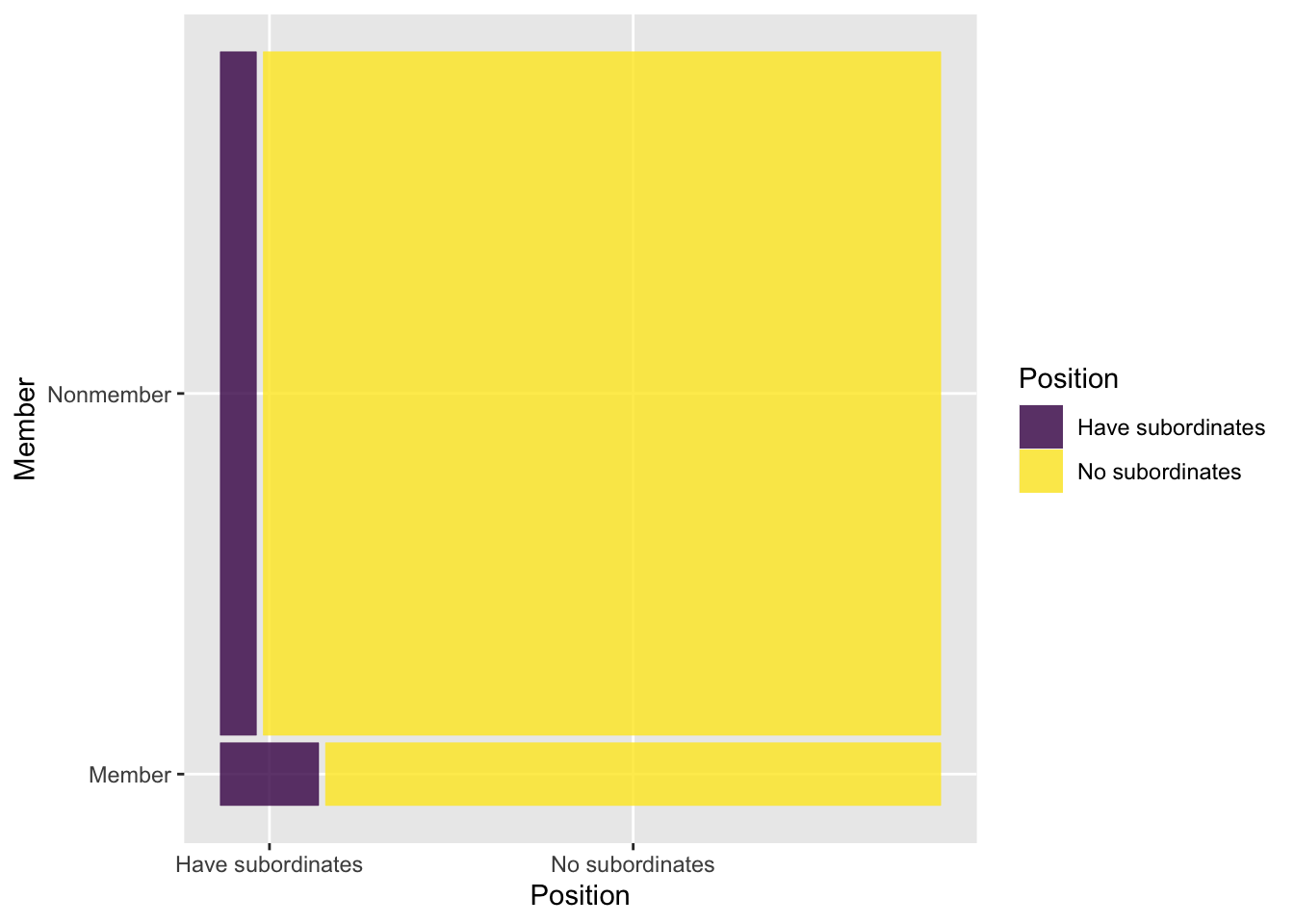
表にaddmargins()で周辺度数を追加する.
# A. 度数(周辺度数の追加)
tab_2.1 |> addmargins() Position
Member Have subordinates No subordinates Sum
Member 40 250 290
Nonmember 160 3000 3160
Sum 200 3250 3450表の数字を用いてオッズ比を計算する.
# B. Odds
x <- tab_2.1
# 1行1列と1行2列
x[1,1]/x[1,2][1] 0.16# 2行1列と2行2列
x[2,1]/x[2,2][1] 0.05333333# C. Odds ratio
OR <- (x[1,1]/x[1,2]) / (x[2,1]/x[2,2])
OR[1] 3(対数)オッズ比の信頼区間をもとめる.
# 対数オッズの標準誤差を求める
SD <- sqrt(1/x[1,1] + 1/x[1,2] + 1/x[2,1] + 1/x[2,2])
# 対数オッズ比の信頼区間を求める
CI_log_OR <- log(OR) + qnorm(c(0.025, 0.975)) * SD
CI_log_OR[1] 0.7288936 1.4683310# オッズ比の信頼区間を求める
exp(CI_log_OR)[1] 2.072786 4.341982DescToolsパッケージのOddsRatio関数を用いてオッズ比を求める.conf.level = 0.95とすることで信頼区間を求めることもできる. 先程計算したものと値が一致している.
# OddsRatio関数を用いる
OddsRatio(tab_2.1, conf.level = 0.95)odds ratio lwr.ci upr.ci
3.000000 2.072786 4.341982
関数の中身を確認する.
OddsRatio()がどのような処理をしているのかについてはOddsRatioと入力し,関数の中身をみることで確認できる.ただし,UseMethod("OddsRatio")となっており,詳細が分からないことがある.その場合は,methods()を用いる.そして,OddsRatio.default*のように*がついているものについてDescTools:::OddsRatio.defaultのように入力することで中身を確認することができる.getAnywhere(OddsRatio.default)としてもよい.
# OddsRatio関数の中身を確認
OddsRatio
# methods関数を用いてどこにアクセスすればよいかを確認する
methods(OddsRatio)
# DescTools関数のOddsRatio.defaultの中身を確認する
DescTools:::OddsRatio.default
# getAnywhereを利用する
getAnywhere(OddsRatio.default)さらに詳細な結果をみたければDescToolsパッケージのDescを用いる.
# 詳細なクロス表の分析
Desc(tab_2.1)──────────────────────────────────────────────────────────────────────────────
tab_2.1 (table)
Summary:
n: 3'450, rows: 2, columns: 2
Pearson's Chi-squared test (cont. adj):
X-squared = 35.487, df = 1, p-value = 2.568e-09
Fisher's exact test p-value = 9.541e-08
McNemar's chi-squared = 19.32, df = 1, p-value = 1.106e-05
estimate lwr.ci upr.ci'
odds ratio 3.0000 2.0728 4.3420
rel. risk (col1) 2.7241 1.9684 3.7700
rel. risk (col2) 0.9080 0.8666 0.9515
prop. diff 0.0873 0.0514 0.1323
Contingency Coeff. 0.103
Cramer's V 0.104
Kendall Tau-b 0.104
Position Have subordinates No subordinates Sum
Member
Member freq 40 250 290
perc 1.2% 7.2% 8.4%
p.row 13.8% 86.2% .
p.col 20.0% 7.7% .
Nonmember freq 160 3'000 3'160
perc 4.6% 87.0% 91.6%
p.row 5.1% 94.9% .
p.col 80.0% 92.3% .
Sum freq 200 3'250 3'450
perc 5.8% 94.2% 100.0%
p.row . . .
p.col . . .
────────────────────
' 95% conf. level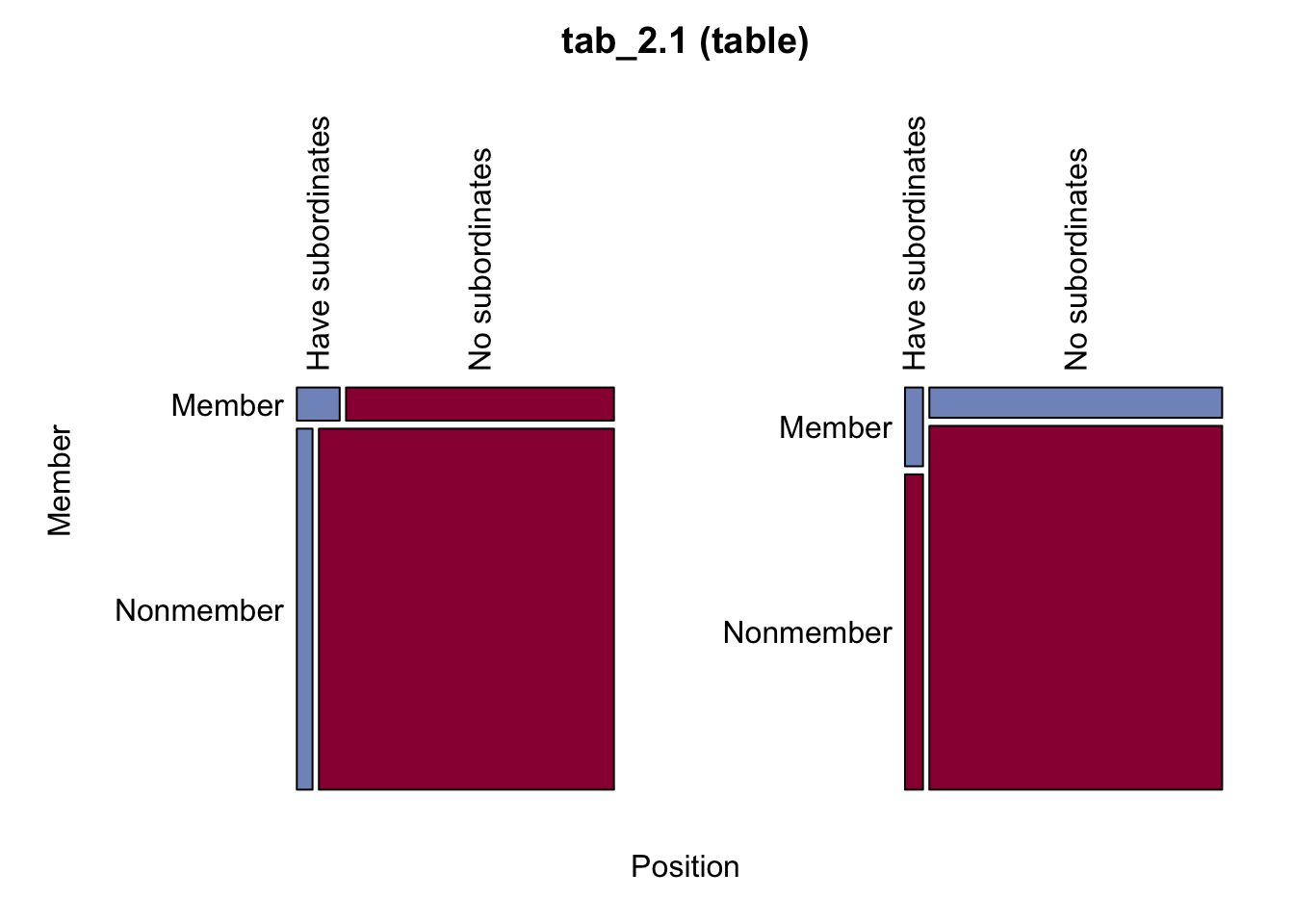
次にセルの組み合わせを単位とした集計データを作成し,gnmを適用することでオッズ比を求めてみたい.gl()はn個の水準のある因子を作成する.kは各水準を何度繰り返すのかを指定する.lengthでベクトルの長さを設定することで,その長さになるまで因子の作成が繰り返される.
# 度数のベクトル
Freq[1] 40 250 160 3000# 行変数 1,2の水準のそれぞれを2回くりかえす
COMM <- gl(n = 2, k = 2) # rep(c(1, 2), each = 2) |> factor()
COMM[1] 1 1 2 2
Levels: 1 2# 列変数 1,2の水準を大きさが4となるまでそれぞれを1回くりかえす
SUP <- gl(n = 2, k = 1, length = 4) # rep(c(1, 2), times = 2) |> factor()
SUP[1] 1 2 1 2
Levels: 1 2# 度数,行変数,列変数からなるデータを作成
freq_tab_2.1 <- tibble(COMM, SUP, Freq)
# データの確認
freq_tab_2.1# A tibble: 4 × 3
COMM SUP Freq
<fct> <fct> <dbl>
1 1 1 40
2 1 2 250
3 2 1 160
4 2 2 3000分析には通常はglmを用いるが,後の分析とあわせてgnmによって推定する.結果は異ならない.family = poissonという指定を忘れないようにすること.何も指定しないとfamily = gaussianとなり,エラーなどを出さずに通常の線形回帰分析を行ってしまうので注意する.
# gnmで推定
fit <- freq_tab_2.1 |>
gnm(Freq ~ COMM + SUP + COMM:SUP, data = _, family = poisson)
# 結果
summary(fit)
Call:
gnm(formula = Freq ~ COMM + SUP + COMM:SUP, family = poisson,
data = freq_tab_2.1)
Deviance Residuals:
[1] 0 0 0 0
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.6889 0.1581 23.331 < 2e-16 ***
COMM2 1.3863 0.1768 7.842 < 2e-16 ***
SUP2 1.8326 0.1703 10.761 < 2e-16 ***
COMM2:SUP2 1.0986 0.1886 5.824 5.75e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Residual deviance: -5.3113e-13 on 0 degrees of freedom
AIC: 37.649
Number of iterations: 2tidy(fit, conf.int = TRUE)# A tibble: 4 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.69 0.158 23.3 2.17e-120 3.36 3.98
2 COMM2 1.39 0.177 7.84 4.43e- 15 1.05 1.75
3 SUP2 1.83 0.170 10.8 5.24e- 27 1.51 2.18
4 COMM2:SUP2 1.10 0.189 5.82 5.75e- 9 0.718 1.46COMM2:SUP2の係数は1.0986である.これは対数オッズなので,指数関数expを適用してオッズ比を求める.
# Odds ratios fit$coefficientsのCOMM2:SUP2の要素のみを取り出し,指数関数expを適用
fit$coefficients["COMM2:SUP2"] |> exp()COMM2:SUP2
3 fit |> confint("COMM2:SUP2") |> exp() 2.5 % 97.5 %
2.049627 4.301359 次のようにしてもよい.
# 係数の"COMM2:SUP2"の部分のみを取り出し,expを使用
coef(fit)["COMM2:SUP2"] |> exp()COMM2:SUP2
3 # 信頼区間の行が"COMM2:SUP2"の部分のみを取り出し,expを使用
confint(fit)["COMM2:SUP2",] |> exp() 2.5 % 97.5 %
2.049627 4.301359 他の係数についてもまとめて示したければtidy関数を用いる.
# 係数をtidyを用いて表示し,expを適用した新たな変数を作成する.
tidy(fit, conf.int = TRUE) |>
mutate(odds_ratio = exp(estimate),
or_conf.high = exp(conf.high),
or_conf.low = exp(conf.low))# A tibble: 4 × 10
term estimate std.error statistic p.value conf.low conf.high odds_ratio
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Interce… 3.69 0.158 23.3 2.17e-120 3.36 3.98 40.0
2 COMM2 1.39 0.177 7.84 4.43e- 15 1.05 1.75 4.00
3 SUP2 1.83 0.170 10.8 5.24e- 27 1.51 2.18 6.25
4 COMM2:SU… 1.10 0.189 5.82 5.75e- 9 0.718 1.46 3.00
# ℹ 2 more variables: or_conf.high <dbl>, or_conf.low <dbl>2.3 表2.3A (p.32)
まずは表2.3Aを作成する.値をベクトルの形式で入力する.
# 表2.3Aの値を入力
Freq <- c( 39, 50, 18, 4,
140, 178, 85, 23,
108, 195, 97, 23,
238, 598, 363, 111,
78, 250, 150, 55,
50, 200, 208, 74,
8, 29, 46, 21)ベクトルのデータをmatrixで行列にし,最終的にはas.tableでtable形式にする.
# データを表形式に変換
tab_2.3A <- matrix(
Freq,
nrow = 7,
ncol = 4,
byrow = TRUE,
dimnames = c(list(
polviews = c(
"Strongly liberal",
"Liberal",
"Slightly liberal",
"Moderate",
"Slightly conservative",
"Conservative",
"Strongly conservative"),
fefam = c("Strongly Disagree",
"Disagree",
"Agree",
"Strongly agree")
))) |> as.table()
tab_2.3A fefam
polviews Strongly Disagree Disagree Agree Strongly agree
Strongly liberal 39 50 18 4
Liberal 140 178 85 23
Slightly liberal 108 195 97 23
Moderate 238 598 363 111
Slightly conservative 78 250 150 55
Conservative 50 200 208 74
Strongly conservative 8 29 46 21# 度数,行変数,列変数からなる集計データを作成
polviews <- gl(n = 7, k = 4) # 1-7までの各数字について4つ値を出す
fefam <- gl(n = 4, k = 1, length = 28) # 1-4までの数字の列を長さが28になるまで繰り返す
# Freq, polviews, fefamからなるデータを作成
freq_tab_2.3A <- tibble(Freq, polviews, fefam)
freq_tab_2.3A# A tibble: 28 × 3
Freq polviews fefam
<dbl> <fct> <fct>
1 39 1 1
2 50 1 2
3 18 1 3
4 4 1 4
5 140 2 1
6 178 2 2
7 85 2 3
8 23 2 4
9 108 3 1
10 195 3 2
# ℹ 18 more rows- なお
tab_2.3Aに対して,data.frameを適用しても集計データは作成される.tableの行変数と列変数が指定されていないと,行変数はVar1,列変数はVar2となるので,必要に応じて名前をrenameで修正する.
# 表データにdata.frameを適用し,tibble形式で表示
data.frame(tab_2.3A) |> tibble()# A tibble: 28 × 3
polviews fefam Freq
<fct> <fct> <dbl>
1 Strongly liberal Strongly Disagree 39
2 Liberal Strongly Disagree 140
3 Slightly liberal Strongly Disagree 108
4 Moderate Strongly Disagree 238
5 Slightly conservative Strongly Disagree 78
6 Conservative Strongly Disagree 50
7 Strongly conservative Strongly Disagree 8
8 Strongly liberal Disagree 50
9 Liberal Disagree 178
10 Slightly liberal Disagree 195
# ℹ 18 more rows以下では複数のモデルの適合度を比較する.そこで,モデル適合度を表示するための関数を作成する.モデルはすべてgnmによって推定されることを前提としている.glmの場合はエラーが出るので注意すること.
# 引数となるobjはgnmの結果
model.summary <- function(obj, Model = NULL){
if (sum(class(obj) == "gnm") != 1)
stop("estimate with gnm")
aic <- obj$deviance - obj$df * 2 # AIC(L2)
bic <- obj$deviance - obj$df * log(sum(obj$y)) #BIC(L2)
delta <- 100 * sum(abs(obj$y - obj$fitted.values)) / (2 * sum(obj$y))
p <- pchisq(obj$deviance, obj$df, lower.tail = FALSE) #p<-ifelse(p<0.001,"<0.001",p)
result <- matrix(0, 1, 7)
if (is.null(Model)){
Model <- deparse(substitute(obj))
}
result <- tibble(
"Model Description" = Model,
"df" = obj$df,
"L2" = obj$deviance,
#"AIC(L2)" = aic,
"BIC" = bic,
"Delta" = delta,
"p" = p
)
return(result)
}コントラストがデフォルトのfactor = "contr.treatment"とordered = "contr.poly"になっているのかを確認する.
# デフォルトのcontrasts
options("contrasts")$contrasts
factor ordered
"contr.treatment" "contr.poly" # defaultのcontrastsの設定(ここでは特に意味はない.constrastをいじった後にデフォルトに戻す)
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))行スコアと列スコアを用いるので,まずas.integerを用いて行スコア(Rscore)と列スコア(Cscore)の変数を作成する.
# 行変数と列変数の整数値を作成
freq_tab_2.3A <- freq_tab_2.3A |>
mutate(Rscore = as.integer(polviews),
Rscore = Rscore - mean(Rscore),
Cscore = as.integer(fefam),
Cscore = Cscore - mean(Cscore))
freq_tab_2.3A# A tibble: 28 × 5
Freq polviews fefam Rscore Cscore
<dbl> <fct> <fct> <dbl> <dbl>
1 39 1 1 -3 -1.5
2 50 1 2 -3 -0.5
3 18 1 3 -3 0.5
4 4 1 4 -3 1.5
5 140 2 1 -2 -1.5
6 178 2 2 -2 -0.5
7 85 2 3 -2 0.5
8 23 2 4 -2 1.5
9 108 3 1 -1 -1.5
10 195 3 2 -1 -0.5
# ℹ 18 more rows2.3.1 独立モデル
独立モデルは次のようになる.
# 1. O: Independence/Null Association Model
O <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam,
family = poisson,
data = _,
tolerance = 1e-12
)
# 結果
summary(O)
Call:
gnm(formula = Freq ~ polviews + fefam, family = poisson, data = freq_tab_2.3A,
tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-5.7415 -2.5344 -0.4283 1.5557 5.8265
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.06035 0.10115 30.256 < 2e-16 ***
polviews2 1.34491 0.10657 12.620 < 2e-16 ***
polviews3 1.33784 0.10664 12.545 < 2e-16 ***
polviews4 2.46825 0.09886 24.968 < 2e-16 ***
polviews5 1.56899 0.10433 15.038 < 2e-16 ***
polviews6 1.56711 0.10435 15.018 < 2e-16 ***
polviews7 -0.06514 0.13647 -0.477 0.633
fefam2 0.81947 0.04669 17.553 < 2e-16 ***
fefam3 0.38044 0.05047 7.538 4.76e-14 ***
fefam4 -0.75396 0.06876 -10.965 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Residual deviance: 211.7 on 18 degrees of freedom
AIC: 403.05
Number of iterations: 5tidy(O)# A tibble: 10 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.06 0.101 30.3 4.36e-201
2 polviews2 1.34 0.107 12.6 1.63e- 36
3 polviews3 1.34 0.107 12.5 4.24e- 36
4 polviews4 2.47 0.0989 25.0 1.35e-137
5 polviews5 1.57 0.104 15.0 4.11e- 51
6 polviews6 1.57 0.104 15.0 5.60e- 51
7 polviews7 -0.0651 0.136 -0.477 6.33e- 1
8 fefam2 0.819 0.0467 17.6 5.65e- 69
9 fefam3 0.380 0.0505 7.54 4.76e- 14
10 fefam4 -0.754 0.0688 -11.0 5.65e- 28glance(O)# A tibble: 1 × 8
null.deviance df.null logLik AIC BIC deviance df.residual nobs
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
1 NA NA -192. 403. 416. 212. 18 28先ほど作成した適合度の関数を用いる.2つめの引数はモデルの名前の詳細を記述可能だが,これは省略してもよい.省略するとモデルをフィットさせた結果のオブジェクトの名前が表示される.
# モデル適合度
model.summary(O, "O:Independent")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 O:Independent 18 212. 65.1 8.09 4.54e-35テキストの表2.4と同じ結果になっているのかを確認してみる.期待度数は様々な方法でとりだすことができる.ここでは元の観測度数の値も表示されるbroomパッケージのaugment関数を用いる.
# broomのaugmentで期待度数を求め,それをもとにL2とBICを計算
broom::augment(O, newdata = freq_tab_2.3A, type.predict = "response") |>
dplyr::summarise(L2 = sum(Freq * log(Freq / .fitted)) * 2,
BIC = L2 - summary(O)$df.residual * log(sum(Freq)))# A tibble: 1 × 2
L2 BIC
<dbl> <dbl>
1 212. 65.1# predict関数で期待度数を求める
predict(O, newdata = freq_tab_2.3A, type = "response") 1 2 3 4 5 6 7 8
21.33498 48.41524 31.21169 10.03809 81.88020 185.80983 119.78540 38.52457
9 10 11 12 13 14 15 16
81.30358 184.50131 118.94184 38.25327 251.79122 571.38703 368.35417 118.46758
17 18 19 20 21 22 23 24
102.44635 232.48037 149.87235 48.20093 102.25414 232.04420 149.59116 48.11050
25 26 27 28
19.98953 45.36202 29.24338 9.40506 # 結果から期待度数を取り出す.
O$fitted.values 1 2 3 4 5 6 7 8
21.33498 48.41524 31.21169 10.03809 81.88020 185.80983 119.78540 38.52457
9 10 11 12 13 14 15 16
81.30358 184.50131 118.94184 38.25327 251.79122 571.38703 368.35417 118.46758
17 18 19 20 21 22 23 24
102.44635 232.48037 149.87235 48.20093 102.25414 232.04420 149.59116 48.11050
25 26 27 28
19.98953 45.36202 29.24338 9.40506 2.3.2 一様連関モデル
一様連関モデルでは先ほど作成した行変数と列変数の整数スコアの積であるRscore:Cscoreを加える.Rscore*CscoreあるいはI(Rscore*Cscore)でもよい.
# 2. U: Uniform Association Model
U <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Rscore:Cscore,
family = poisson,
data = _,
tolerance = 1e-12)# 結果
summary(U)
Call:
gnm(formula = Freq ~ polviews + fefam + Rscore:Cscore, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.62563 -0.41050 -0.06989 0.53746 1.67998
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.77240 0.10449 26.533 < 2e-16 ***
polviews2 1.46434 0.10748 13.625 < 2e-16 ***
polviews3 1.55049 0.10942 14.170 < 2e-16 ***
polviews4 2.74597 0.10368 26.485 < 2e-16 ***
polviews5 1.88202 0.10973 17.151 < 2e-16 ***
polviews6 1.88457 0.10937 17.231 < 2e-16 ***
polviews7 0.22533 0.13937 1.617 0.106
fefam2 0.85993 0.04746 18.117 < 2e-16 ***
fefam3 0.38502 0.05144 7.484 7.19e-14 ***
fefam4 -0.85901 0.07109 -12.083 < 2e-16 ***
Rscore:Cscore 0.20211 0.01520 13.299 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Residual deviance: 20.125 on 17 degrees of freedom
AIC: 213.48
Number of iterations: 4# 信頼区間もあわせてtidyで表示
tidy(U, conf.int = TRUE)# A tibble: 11 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 2.77 0.104 26.5 4.02e-155 2.56 2.97
2 polviews2 1.46 0.107 13.6 2.85e- 42 1.26 1.68
3 polviews3 1.55 0.109 14.2 1.41e- 45 1.34 1.77
4 polviews4 2.75 0.104 26.5 1.45e-154 2.55 2.95
5 polviews5 1.88 0.110 17.2 6.15e- 66 1.67 2.10
6 polviews6 1.88 0.109 17.2 1.55e- 66 1.67 2.10
7 polviews7 0.225 0.139 1.62 1.06e- 1 -0.0485 0.499
8 fefam2 0.860 0.0475 18.1 2.33e- 73 0.767 0.954
9 fefam3 0.385 0.0514 7.48 7.19e- 14 0.285 0.486
10 fefam4 -0.859 0.0711 -12.1 1.30e- 33 -1.000 -0.721
11 Rscore:Cscore 0.202 0.0152 13.3 2.33e- 40 0.173 0.232表2.4Aと同じ結果になっているのかを確認する.
# モデル適合度
model.summary(U, "U:Uniform")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 U:Uniform 17 20.1 -118. 2.77 0.268モデル行列を確認するのもよいだろう.
# model.matrixを適用し,ユニークな値だけを表示
model.matrix(U) |> unique() (Intercept) polviews2 polviews3 polviews4 polviews5 polviews6 polviews7
1 1 0 0 0 0 0 0
2 1 0 0 0 0 0 0
3 1 0 0 0 0 0 0
4 1 0 0 0 0 0 0
5 1 1 0 0 0 0 0
6 1 1 0 0 0 0 0
7 1 1 0 0 0 0 0
8 1 1 0 0 0 0 0
9 1 0 1 0 0 0 0
10 1 0 1 0 0 0 0
11 1 0 1 0 0 0 0
12 1 0 1 0 0 0 0
13 1 0 0 1 0 0 0
14 1 0 0 1 0 0 0
15 1 0 0 1 0 0 0
16 1 0 0 1 0 0 0
17 1 0 0 0 1 0 0
18 1 0 0 0 1 0 0
19 1 0 0 0 1 0 0
20 1 0 0 0 1 0 0
21 1 0 0 0 0 1 0
22 1 0 0 0 0 1 0
23 1 0 0 0 0 1 0
24 1 0 0 0 0 1 0
25 1 0 0 0 0 0 1
26 1 0 0 0 0 0 1
27 1 0 0 0 0 0 1
28 1 0 0 0 0 0 1
fefam2 fefam3 fefam4 Rscore:Cscore
1 0 0 0 4.5
2 1 0 0 1.5
3 0 1 0 -1.5
4 0 0 1 -4.5
5 0 0 0 3.0
6 1 0 0 1.0
7 0 1 0 -1.0
8 0 0 1 -3.0
9 0 0 0 1.5
10 1 0 0 0.5
11 0 1 0 -0.5
12 0 0 1 -1.5
13 0 0 0 0.0
14 1 0 0 0.0
15 0 1 0 0.0
16 0 0 1 0.0
17 0 0 0 -1.5
18 1 0 0 -0.5
19 0 1 0 0.5
20 0 0 1 1.5
21 0 0 0 -3.0
22 1 0 0 -1.0
23 0 1 0 1.0
24 0 0 1 3.0
25 0 0 0 -4.5
26 1 0 0 -1.5
27 0 1 0 1.5
28 0 0 1 4.52.3.3 行効果モデル
contrastを修正し,polviewsの係数のすべてを足すと0になるように効果コーディングを行ってる.なお行変数と列スコアの積についてはCscore*polviewsとし,Cscore:polviewsとしない.
# contrastを修正している.
options(contrasts = c(factor = "contr.sum",
ordered = "contr.treatment"))
options("contrasts")$contrasts
factor ordered
"contr.sum" "contr.treatment" # 3. R: Row Effect Model
R <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Cscore*polviews,
family = poisson,
data = _,
tolerance = 1e-12)
# 結果
summary(R)
Call:
gnm(formula = Freq ~ polviews + fefam + Cscore * polviews, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.5962 -0.4603 0.0477 0.3840 1.5700
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.262045 0.029618 143.902 < 2e-16 ***
polviews1 -1.356438 0.106013 -12.795 < 2e-16 ***
polviews2 0.075995 0.055906 1.359 0.1740
polviews3 0.142487 0.053465 2.665 0.0077 **
polviews4 1.357080 0.036418 37.264 < 2e-16 ***
polviews5 0.478200 0.046111 10.371 < 2e-16 ***
polviews6 0.489287 0.045766 10.691 < 2e-16 ***
fefam1 -0.112887 0.046238 -2.441 0.0146 *
fefam2 0.758505 0.030086 25.211 < 2e-16 ***
fefam3 0.295555 0.032630 9.058 < 2e-16 ***
Cscore 0.000000 NA NA NA
polviews1:Cscore -0.558727 0.107668 -5.189 2.11e-07 ***
polviews2:Cscore -0.405076 0.059149 -6.848 7.47e-12 ***
polviews3:Cscore -0.248459 0.057741 -4.303 1.69e-05 ***
polviews4:Cscore 0.008764 0.039709 0.221 0.8253
polviews5:Cscore 0.112245 0.051284 2.189 0.0286 *
polviews6:Cscore 0.419079 0.051434 8.148 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 15.906 on 12 degrees of freedom
AIC: 219.26
Number of iterations: 4# 信頼区間もあわせてtidyで表示
tidy(R, conf.int = TRUE)# A tibble: 17 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 4.26 0.0296 144. 0 4.20 4.32
2 polviews1 -1.36 0.106 -12.8 1.75e- 37 -1.57 -1.16
3 polviews2 0.0760 0.0559 1.36 1.74e- 1 -0.0351 0.184
4 polviews3 0.142 0.0535 2.67 7.70e- 3 0.0365 0.246
5 polviews4 1.36 0.0364 37.3 6.33e-304 1.29 1.43
6 polviews5 0.478 0.0461 10.4 3.38e- 25 0.387 0.568
7 polviews6 0.489 0.0458 10.7 1.12e- 26 0.399 0.579
8 fefam1 -0.113 0.0462 -2.44 1.46e- 2 -0.204 -0.0224
9 fefam2 0.759 0.0301 25.2 3.04e-140 0.700 0.818
10 fefam3 0.296 0.0326 9.06 1.33e- 19 0.232 0.359
11 Cscore 0 NA NA NA NA NA
12 polviews1:Cscore -0.559 0.108 -5.19 2.11e- 7 -0.774 -0.351
13 polviews2:Cscore -0.405 0.0591 -6.85 7.47e- 12 -0.522 -0.290
14 polviews3:Cscore -0.248 0.0577 -4.30 1.69e- 5 -0.362 -0.136
15 polviews4:Cscore 0.00876 0.0397 0.221 8.25e- 1 -0.0690 0.0867
16 polviews5:Cscore 0.112 0.0513 2.19 2.86e- 2 0.0117 0.213
17 polviews6:Cscore 0.419 0.0514 8.15 3.70e- 16 0.319 0.520 # モデル適合度
model.summary(R, "R:Row effect")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 R:Row effect 12 15.9 -81.8 2.47 0.196# モデル行列の確認
model.matrix(R) |> unique() (Intercept) polviews1 polviews2 polviews3 polviews4 polviews5 polviews6
1 1 1 0 0 0 0 0
2 1 1 0 0 0 0 0
3 1 1 0 0 0 0 0
4 1 1 0 0 0 0 0
5 1 0 1 0 0 0 0
6 1 0 1 0 0 0 0
7 1 0 1 0 0 0 0
8 1 0 1 0 0 0 0
9 1 0 0 1 0 0 0
10 1 0 0 1 0 0 0
11 1 0 0 1 0 0 0
12 1 0 0 1 0 0 0
13 1 0 0 0 1 0 0
14 1 0 0 0 1 0 0
15 1 0 0 0 1 0 0
16 1 0 0 0 1 0 0
17 1 0 0 0 0 1 0
18 1 0 0 0 0 1 0
19 1 0 0 0 0 1 0
20 1 0 0 0 0 1 0
21 1 0 0 0 0 0 1
22 1 0 0 0 0 0 1
23 1 0 0 0 0 0 1
24 1 0 0 0 0 0 1
25 1 -1 -1 -1 -1 -1 -1
26 1 -1 -1 -1 -1 -1 -1
27 1 -1 -1 -1 -1 -1 -1
28 1 -1 -1 -1 -1 -1 -1
fefam1 fefam2 fefam3 Cscore polviews1:Cscore polviews2:Cscore
1 1 0 0 -1.5 -1.5 0.0
2 0 1 0 -0.5 -0.5 0.0
3 0 0 1 0.5 0.5 0.0
4 -1 -1 -1 1.5 1.5 0.0
5 1 0 0 -1.5 0.0 -1.5
6 0 1 0 -0.5 0.0 -0.5
7 0 0 1 0.5 0.0 0.5
8 -1 -1 -1 1.5 0.0 1.5
9 1 0 0 -1.5 0.0 0.0
10 0 1 0 -0.5 0.0 0.0
11 0 0 1 0.5 0.0 0.0
12 -1 -1 -1 1.5 0.0 0.0
13 1 0 0 -1.5 0.0 0.0
14 0 1 0 -0.5 0.0 0.0
15 0 0 1 0.5 0.0 0.0
16 -1 -1 -1 1.5 0.0 0.0
17 1 0 0 -1.5 0.0 0.0
18 0 1 0 -0.5 0.0 0.0
19 0 0 1 0.5 0.0 0.0
20 -1 -1 -1 1.5 0.0 0.0
21 1 0 0 -1.5 0.0 0.0
22 0 1 0 -0.5 0.0 0.0
23 0 0 1 0.5 0.0 0.0
24 -1 -1 -1 1.5 0.0 0.0
25 1 0 0 -1.5 1.5 1.5
26 0 1 0 -0.5 0.5 0.5
27 0 0 1 0.5 -0.5 -0.5
28 -1 -1 -1 1.5 -1.5 -1.5
polviews3:Cscore polviews4:Cscore polviews5:Cscore polviews6:Cscore
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0
5 0.0 0.0 0.0 0.0
6 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0
9 -1.5 0.0 0.0 0.0
10 -0.5 0.0 0.0 0.0
11 0.5 0.0 0.0 0.0
12 1.5 0.0 0.0 0.0
13 0.0 -1.5 0.0 0.0
14 0.0 -0.5 0.0 0.0
15 0.0 0.5 0.0 0.0
16 0.0 1.5 0.0 0.0
17 0.0 0.0 -1.5 0.0
18 0.0 0.0 -0.5 0.0
19 0.0 0.0 0.5 0.0
20 0.0 0.0 1.5 0.0
21 0.0 0.0 0.0 -1.5
22 0.0 0.0 0.0 -0.5
23 0.0 0.0 0.0 0.5
24 0.0 0.0 0.0 1.5
25 1.5 1.5 1.5 1.5
26 0.5 0.5 0.5 0.5
27 -0.5 -0.5 -0.5 -0.5
28 -1.5 -1.5 -1.5 -1.5表2.4の適合度を確認しよう.また,パラメータ推定値については,表2.5のBから確認する. Rの結果では,polviews1からpolviews6までの結果が表示されているが,polviews7は示されていない.パラメータのすべての値を足すと0となることから(\(\sum \tau_i^A=0\)),polviews7の係数は0-(-0.6721737)=0.6721737となる.これをRで計算するためには係数を取り出し,それらを足したものを0から引けばよい.
# R
# 取り出す係数を探す
pickCoef(R, ":Cscore")polviews1:Cscore polviews2:Cscore polviews3:Cscore polviews4:Cscore
12 13 14 15
polviews5:Cscore polviews6:Cscore
16 17 # 12から17番目の係数を取り出し,足す
R$coefficients[12:17] |> sum()[1] -0.6721737# 次のようにもできる
R$coefficients[pickCoef(R, ":Cscore")] |> sum()[1] -0.6721737# 0から足したものを引く
0 - (R$coefficients[pickCoef(R, ":Cscore")] |> sum())[1] 0.6721737contrastsをもとに戻して同様の分析を行う. 今度はpolviews1:Cscoreの係数が省略されているが,この値は0である(\(\tau_1^A=0\)).
# alternative (default)
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))
Ralt <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Cscore*polviews,
family = poisson,
data = _,
tolerance = 1e-12)結果は表2.5Bの「他の正規化」の行を確認して欲しい.
# 結果
summary(Ralt)
Call:
gnm(formula = Freq ~ polviews + fefam + Cscore * polviews, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.5962 -0.4603 0.0477 0.3840 1.5700
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.6308 0.1443 25.160 < 2e-16 ***
polviews2 1.4324 0.1342 10.670 < 2e-16 ***
polviews3 1.4989 0.1329 11.279 < 2e-16 ***
polviews4 2.7135 0.1246 21.776 < 2e-16 ***
polviews5 1.8346 0.1290 14.218 < 2e-16 ***
polviews6 1.8457 0.1289 14.323 < 2e-16 ***
polviews7 0.1698 0.1589 1.069 0.28508
fefam2 0.3127 0.1265 2.471 0.01345 *
fefam3 -0.7090 0.2447 -2.897 0.00376 **
fefam4 -2.5045 0.3703 -6.763 1.36e-11 ***
Cscore 0.0000 NA NA NA
polviews2:Cscore 0.1537 0.1362 1.128 0.25925
polviews3:Cscore 0.3103 0.1357 2.287 0.02219 *
polviews4:Cscore 0.5675 0.1268 4.477 7.58e-06 ***
polviews5:Cscore 0.6710 0.1326 5.059 4.21e-07 ***
polviews6:Cscore 0.9778 0.1331 7.346 2.04e-13 ***
polviews7:Cscore 1.2309 0.1678 7.335 2.22e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 15.906 on 12 degrees of freedom
AIC: 219.26
Number of iterations: 4# 信頼区間もあわせてtidyで表示
tidy(Ralt, conf.int = TRUE)# A tibble: 17 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.63 0.144 25.2 1.10e-139 3.34 3.90
2 polviews2 1.43 0.134 10.7 1.40e- 26 1.18 1.70
3 polviews3 1.50 0.133 11.3 1.66e- 29 1.25 1.77
4 polviews4 2.71 0.125 21.8 3.89e-105 2.48 2.97
5 polviews5 1.83 0.129 14.2 7.05e- 46 1.59 2.10
6 polviews6 1.85 0.129 14.3 1.58e- 46 1.60 2.11
7 polviews7 0.170 0.159 1.07 2.85e- 1 -0.139 0.486
8 fefam2 0.313 0.127 2.47 1.35e- 2 0.0616 0.558
9 fefam3 -0.709 0.245 -2.90 3.76e- 3 -1.20 -0.237
10 fefam4 -2.50 0.370 -6.76 1.36e- 11 -3.24 -1.79
11 Cscore 0 NA NA NA NA NA
12 polviews2:Cscore 0.154 0.136 1.13 2.59e- 1 -0.110 0.424
13 polviews3:Cscore 0.310 0.136 2.29 2.22e- 2 0.0476 0.580
14 polviews4:Cscore 0.567 0.127 4.48 7.58e- 6 0.323 0.820
15 polviews5:Cscore 0.671 0.133 5.06 4.21e- 7 0.415 0.935
16 polviews6:Cscore 0.978 0.133 7.35 2.04e- 13 0.721 1.24
17 polviews7:Cscore 1.23 0.168 7.33 2.22e- 13 0.905 1.56 モデルの適合度は全く同じであることがわかる.
# モデル適合度
model.summary(R, "R: Row effect (effect coding)")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 R: Row effect (effect coding) 12 15.9 -81.8 2.47 0.196model.summary(Ralt, "R: Row effect (dummy coding)")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 R: Row effect (dummy coding) 12 15.9 -81.8 2.47 0.196# モデル行列の確認
model.matrix(Ralt) |> unique() (Intercept) polviews2 polviews3 polviews4 polviews5 polviews6 polviews7
1 1 0 0 0 0 0 0
2 1 0 0 0 0 0 0
3 1 0 0 0 0 0 0
4 1 0 0 0 0 0 0
5 1 1 0 0 0 0 0
6 1 1 0 0 0 0 0
7 1 1 0 0 0 0 0
8 1 1 0 0 0 0 0
9 1 0 1 0 0 0 0
10 1 0 1 0 0 0 0
11 1 0 1 0 0 0 0
12 1 0 1 0 0 0 0
13 1 0 0 1 0 0 0
14 1 0 0 1 0 0 0
15 1 0 0 1 0 0 0
16 1 0 0 1 0 0 0
17 1 0 0 0 1 0 0
18 1 0 0 0 1 0 0
19 1 0 0 0 1 0 0
20 1 0 0 0 1 0 0
21 1 0 0 0 0 1 0
22 1 0 0 0 0 1 0
23 1 0 0 0 0 1 0
24 1 0 0 0 0 1 0
25 1 0 0 0 0 0 1
26 1 0 0 0 0 0 1
27 1 0 0 0 0 0 1
28 1 0 0 0 0 0 1
fefam2 fefam3 fefam4 Cscore polviews2:Cscore polviews3:Cscore
1 0 0 0 -1.5 0.0 0.0
2 1 0 0 -0.5 0.0 0.0
3 0 1 0 0.5 0.0 0.0
4 0 0 1 1.5 0.0 0.0
5 0 0 0 -1.5 -1.5 0.0
6 1 0 0 -0.5 -0.5 0.0
7 0 1 0 0.5 0.5 0.0
8 0 0 1 1.5 1.5 0.0
9 0 0 0 -1.5 0.0 -1.5
10 1 0 0 -0.5 0.0 -0.5
11 0 1 0 0.5 0.0 0.5
12 0 0 1 1.5 0.0 1.5
13 0 0 0 -1.5 0.0 0.0
14 1 0 0 -0.5 0.0 0.0
15 0 1 0 0.5 0.0 0.0
16 0 0 1 1.5 0.0 0.0
17 0 0 0 -1.5 0.0 0.0
18 1 0 0 -0.5 0.0 0.0
19 0 1 0 0.5 0.0 0.0
20 0 0 1 1.5 0.0 0.0
21 0 0 0 -1.5 0.0 0.0
22 1 0 0 -0.5 0.0 0.0
23 0 1 0 0.5 0.0 0.0
24 0 0 1 1.5 0.0 0.0
25 0 0 0 -1.5 0.0 0.0
26 1 0 0 -0.5 0.0 0.0
27 0 1 0 0.5 0.0 0.0
28 0 0 1 1.5 0.0 0.0
polviews4:Cscore polviews5:Cscore polviews6:Cscore polviews7:Cscore
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0
5 0.0 0.0 0.0 0.0
6 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0
9 0.0 0.0 0.0 0.0
10 0.0 0.0 0.0 0.0
11 0.0 0.0 0.0 0.0
12 0.0 0.0 0.0 0.0
13 -1.5 0.0 0.0 0.0
14 -0.5 0.0 0.0 0.0
15 0.5 0.0 0.0 0.0
16 1.5 0.0 0.0 0.0
17 0.0 -1.5 0.0 0.0
18 0.0 -0.5 0.0 0.0
19 0.0 0.5 0.0 0.0
20 0.0 1.5 0.0 0.0
21 0.0 0.0 -1.5 0.0
22 0.0 0.0 -0.5 0.0
23 0.0 0.0 0.5 0.0
24 0.0 0.0 1.5 0.0
25 0.0 0.0 0.0 -1.5
26 0.0 0.0 0.0 -0.5
27 0.0 0.0 0.0 0.5
28 0.0 0.0 0.0 1.52.4 列効果モデル
列効果モデルは行効果モデルと同様の方法で推定すればよい.まずは効果コーディングで推定し,その後にダミーコーディングで推定する.
# contrast
options(contrasts = c(factor = "contr.sum",
ordered = "contr.treatment"))
# 4. C: Column Effect Model
C <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Rscore*fefam, family = poisson,
data = _,
tolerance = 1e-12)
# 結果
summary(C)
Call:
gnm(formula = Freq ~ polviews + fefam + Rscore * fefam, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.7572 -0.4920 0.1628 0.4922 1.4247
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.26735 0.02842 150.161 < 2e-16 ***
polviews1 -1.34764 0.08885 -15.167 < 2e-16 ***
polviews2 0.10725 0.05058 2.120 0.033978 *
polviews3 0.17817 0.04852 3.672 0.000241 ***
polviews4 1.35465 0.03449 39.280 < 2e-16 ***
polviews5 0.47060 0.04547 10.349 < 2e-16 ***
polviews6 0.45489 0.04714 9.650 < 2e-16 ***
fefam1 -0.11795 0.03606 -3.271 0.001072 **
fefam2 0.75721 0.02817 26.882 < 2e-16 ***
fefam3 0.27540 0.03195 8.619 < 2e-16 ***
Rscore 0.00000 NA NA NA
fefam1:Rscore -0.32183 0.02601 -12.373 < 2e-16 ***
fefam2:Rscore -0.06518 0.02013 -3.238 0.001203 **
fefam3:Rscore 0.13740 0.02282 6.021 1.73e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 14.237 on 15 degrees of freedom
AIC: 211.59
Number of iterations: 4# 信頼区間もあわせてtidyで表示
tidy(C, conf.int = TRUE)# A tibble: 14 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 4.27 0.0284 150. 0 4.21 4.32
2 polviews1 -1.35 0.0889 -15.2 5.81e- 52 -1.53 -1.18
3 polviews2 0.107 0.0506 2.12 3.40e- 2 0.00729 0.206
4 polviews3 0.178 0.0485 3.67 2.41e- 4 0.0823 0.273
5 polviews4 1.35 0.0345 39.3 0 1.29 1.42
6 polviews5 0.471 0.0455 10.3 4.22e- 25 0.381 0.559
7 polviews6 0.455 0.0471 9.65 4.94e- 22 0.362 0.547
8 fefam1 -0.118 0.0361 -3.27 1.07e- 3 -0.189 -0.0477
9 fefam2 0.757 0.0282 26.9 3.60e-159 0.702 0.813
10 fefam3 0.275 0.0320 8.62 6.77e- 18 0.213 0.338
11 Rscore 0 NA NA NA NA NA
12 fefam1:Rscore -0.322 0.0260 -12.4 3.65e- 35 -0.373 -0.271
13 fefam2:Rscore -0.0652 0.0201 -3.24 1.20e- 3 -0.105 -0.0258
14 fefam3:Rscore 0.137 0.0228 6.02 1.73e- 9 0.0928 0.182 # モデル適合度
model.summary(C, "C:Column effect")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 C:Column effect 15 14.2 -108. 2.32 0.508# モデル行列の確認
model.matrix(C) |> unique() (Intercept) polviews1 polviews2 polviews3 polviews4 polviews5 polviews6
1 1 1 0 0 0 0 0
2 1 1 0 0 0 0 0
3 1 1 0 0 0 0 0
4 1 1 0 0 0 0 0
5 1 0 1 0 0 0 0
6 1 0 1 0 0 0 0
7 1 0 1 0 0 0 0
8 1 0 1 0 0 0 0
9 1 0 0 1 0 0 0
10 1 0 0 1 0 0 0
11 1 0 0 1 0 0 0
12 1 0 0 1 0 0 0
13 1 0 0 0 1 0 0
14 1 0 0 0 1 0 0
15 1 0 0 0 1 0 0
16 1 0 0 0 1 0 0
17 1 0 0 0 0 1 0
18 1 0 0 0 0 1 0
19 1 0 0 0 0 1 0
20 1 0 0 0 0 1 0
21 1 0 0 0 0 0 1
22 1 0 0 0 0 0 1
23 1 0 0 0 0 0 1
24 1 0 0 0 0 0 1
25 1 -1 -1 -1 -1 -1 -1
26 1 -1 -1 -1 -1 -1 -1
27 1 -1 -1 -1 -1 -1 -1
28 1 -1 -1 -1 -1 -1 -1
fefam1 fefam2 fefam3 Rscore fefam1:Rscore fefam2:Rscore fefam3:Rscore
1 1 0 0 -3 -3 0 0
2 0 1 0 -3 0 -3 0
3 0 0 1 -3 0 0 -3
4 -1 -1 -1 -3 3 3 3
5 1 0 0 -2 -2 0 0
6 0 1 0 -2 0 -2 0
7 0 0 1 -2 0 0 -2
8 -1 -1 -1 -2 2 2 2
9 1 0 0 -1 -1 0 0
10 0 1 0 -1 0 -1 0
11 0 0 1 -1 0 0 -1
12 -1 -1 -1 -1 1 1 1
13 1 0 0 0 0 0 0
14 0 1 0 0 0 0 0
15 0 0 1 0 0 0 0
16 -1 -1 -1 0 0 0 0
17 1 0 0 1 1 0 0
18 0 1 0 1 0 1 0
19 0 0 1 1 0 0 1
20 -1 -1 -1 1 -1 -1 -1
21 1 0 0 2 2 0 0
22 0 1 0 2 0 2 0
23 0 0 1 2 0 0 2
24 -1 -1 -1 2 -2 -2 -2
25 1 0 0 3 3 0 0
26 0 1 0 3 0 3 0
27 0 0 1 3 0 0 3
28 -1 -1 -1 3 -3 -3 -3すべてを足すと0となることから(\(\sum \tau_j^B=0\)),polviews7の係数は0-(-0.2496118)=0.2496118となる
pickCoef(C, ":Rscore")fefam1:Rscore fefam2:Rscore fefam3:Rscore
12 13 14 C$coefficients[pickCoef(C, ":Rscore")] |> sum()[1] -0.24961180 - (C$coefficients[pickCoef(C, ":Rscore")] |> sum())[1] 0.2496118以下はダミーコーディングを用いている.
# alternative (default)
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))
# 4. C: Column Effect Model (default)
Calt <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Rscore*fefam,
family = poisson,
data = _,
tolerance = 1e-12)推定値は表2.5Cを確認せよ.
# 結果
summary(Calt)
Call:
gnm(formula = Freq ~ polviews + fefam + Rscore * fefam, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.7572 -0.4920 0.1628 0.4922 1.4247
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.76726 0.11222 33.571 < 2e-16 ***
polviews2 1.13306 0.10785 10.506 < 2e-16 ***
polviews3 0.88215 0.11310 7.800 < 2e-16 ***
polviews4 1.73680 0.11708 14.834 < 2e-16 ***
polviews5 0.53092 0.13848 3.834 0.000126 ***
polviews6 0.19337 0.16048 1.205 0.228239
polviews7 -1.80128 0.20632 -8.730 < 2e-16 ***
fefam2 0.87516 0.04848 18.050 < 2e-16 ***
fefam3 0.39335 0.05298 7.424 1.13e-13 ***
fefam4 -0.79671 0.07451 -10.692 < 2e-16 ***
Rscore 0.00000 NA NA NA
fefam2:Rscore 0.25665 0.03459 7.421 1.17e-13 ***
fefam3:Rscore 0.45924 0.03851 11.926 < 2e-16 ***
fefam4:Rscore 0.57144 0.05297 10.788 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 14.237 on 15 degrees of freedom
AIC: 211.59
Number of iterations: 4# 信頼区間もあわせてtidyで表示
tidy(Calt, conf.int = TRUE)# A tibble: 14 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.77 0.112 33.6 4.50e-247 3.54 3.98
2 polviews2 1.13 0.108 10.5 8.08e- 26 0.926 1.35
3 polviews3 0.882 0.113 7.80 6.20e- 15 0.664 1.11
4 polviews4 1.74 0.117 14.8 8.82e- 50 1.51 1.97
5 polviews5 0.531 0.138 3.83 1.26e- 4 0.262 0.806
6 polviews6 0.193 0.160 1.20 2.28e- 1 -0.119 0.510
7 polviews7 -1.80 0.206 -8.73 2.54e- 18 -2.21 -1.40
8 fefam2 0.875 0.0485 18.1 7.85e- 73 0.781 0.971
9 fefam3 0.393 0.0530 7.42 1.13e- 13 0.290 0.498
10 fefam4 -0.797 0.0745 -10.7 1.11e- 26 -0.944 -0.652
11 Rscore 0 NA NA NA NA NA
12 fefam2:Rscore 0.257 0.0346 7.42 1.17e- 13 0.189 0.325
13 fefam3:Rscore 0.459 0.0385 11.9 8.66e- 33 0.384 0.535
14 fefam4:Rscore 0.571 0.0530 10.8 3.94e- 27 0.468 0.676適合度は効果コーディングとダミーコーディングで変化しない.
# モデル適合度
model.summary(C, "C:Column effect (effect coding)") # A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 C:Column effect (effect coding) 15 14.2 -108. 2.32 0.508model.summary(Calt, "C:Column effect (dummy coding)")# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 C:Column effect (dummy coding) 15 14.2 -108. 2.32 0.508# モデル行列の確認
model.matrix(Calt) |> unique() (Intercept) polviews2 polviews3 polviews4 polviews5 polviews6 polviews7
1 1 0 0 0 0 0 0
2 1 0 0 0 0 0 0
3 1 0 0 0 0 0 0
4 1 0 0 0 0 0 0
5 1 1 0 0 0 0 0
6 1 1 0 0 0 0 0
7 1 1 0 0 0 0 0
8 1 1 0 0 0 0 0
9 1 0 1 0 0 0 0
10 1 0 1 0 0 0 0
11 1 0 1 0 0 0 0
12 1 0 1 0 0 0 0
13 1 0 0 1 0 0 0
14 1 0 0 1 0 0 0
15 1 0 0 1 0 0 0
16 1 0 0 1 0 0 0
17 1 0 0 0 1 0 0
18 1 0 0 0 1 0 0
19 1 0 0 0 1 0 0
20 1 0 0 0 1 0 0
21 1 0 0 0 0 1 0
22 1 0 0 0 0 1 0
23 1 0 0 0 0 1 0
24 1 0 0 0 0 1 0
25 1 0 0 0 0 0 1
26 1 0 0 0 0 0 1
27 1 0 0 0 0 0 1
28 1 0 0 0 0 0 1
fefam2 fefam3 fefam4 Rscore fefam2:Rscore fefam3:Rscore fefam4:Rscore
1 0 0 0 -3 0 0 0
2 1 0 0 -3 -3 0 0
3 0 1 0 -3 0 -3 0
4 0 0 1 -3 0 0 -3
5 0 0 0 -2 0 0 0
6 1 0 0 -2 -2 0 0
7 0 1 0 -2 0 -2 0
8 0 0 1 -2 0 0 -2
9 0 0 0 -1 0 0 0
10 1 0 0 -1 -1 0 0
11 0 1 0 -1 0 -1 0
12 0 0 1 -1 0 0 -1
13 0 0 0 0 0 0 0
14 1 0 0 0 0 0 0
15 0 1 0 0 0 0 0
16 0 0 1 0 0 0 0
17 0 0 0 1 0 0 0
18 1 0 0 1 1 0 0
19 0 1 0 1 0 1 0
20 0 0 1 1 0 0 1
21 0 0 0 2 0 0 0
22 1 0 0 2 2 0 0
23 0 1 0 2 0 2 0
24 0 0 1 2 0 0 2
25 0 0 0 3 0 0 0
26 1 0 0 3 3 0 0
27 0 1 0 3 0 3 0
28 0 0 1 3 0 0 32.5 行・列効果モデル(\(R+C\))
普通に推定しても収束しない.
# コントラスト
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.treatment"))
# 5. R+C: Row and Column Effect Model
# 収束しない
RplusCno <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
family = poisson,
data = _,
tolerance = 1e-12)係数を確認する.この場合,制約は3つ必要であるが2つしかNAとなっていない.テキストや表2.5Dを参照し,どのような制約を課すのかをきめる.ここでは表2.5Dのような制約を課す.
RplusCno
Call:
gnm(formula = Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
family = poisson, data = freq_tab_2.3A, tolerance = 1e-12)
Coefficients:
(Intercept) polviews2 polviews3 polviews4
-4.898e+13 8.575e+12 1.715e+13 2.572e+13
polviews5 polviews6 polviews7 fefam2
3.430e+13 4.287e+13 5.145e+13 1.550e+13
fefam3 fefam4 polviews1:Cscore polviews2:Cscore
3.101e+13 4.651e+13 1.646e+12 -4.070e+12
polviews3:Cscore polviews4:Cscore polviews5:Cscore polviews6:Cscore
-9.787e+12 -1.550e+13 -2.122e+13 -2.694e+13
polviews7:Cscore fefam1:Rscore fefam2:Rscore fefam3:Rscore
-3.265e+13 -1.715e+13 -1.143e+13 -5.717e+12
fefam4:Rscore
NA
Deviance: 8.485116
Pearson chi-squared: 8.477813
Residual df: 8 pickCoef(RplusCno, ":Cscore") # 行効果polviews1:Cscore polviews2:Cscore polviews3:Cscore polviews4:Cscore
11 12 13 14
polviews5:Cscore polviews6:Cscore polviews7:Cscore
15 16 17 pickCoef(RplusCno, ":Rscore") # 列効果fefam1:Rscore fefam2:Rscore fefam3:Rscore fefam4:Rscore
18 19 20 21 あるいは次のように一覧にしてもよい.
# 変数と係数と係数の順番を表示
data.frame(var = names(RplusCno$coefficients),
estimate = RplusCno$coefficients) |>
mutate(estimate = estimate,
number = row_number()) var estimate number
(Intercept) (Intercept) -4.898036e+13 1
polviews2 polviews2 8.574948e+12 2
polviews3 polviews3 1.714990e+13 3
polviews4 polviews4 2.572484e+13 4
polviews5 polviews5 3.429979e+13 5
polviews6 polviews6 4.287474e+13 6
polviews7 polviews7 5.144969e+13 7
fefam2 fefam2 1.550368e+13 8
fefam3 fefam3 3.100736e+13 9
fefam4 fefam4 4.651103e+13 10
polviews1:Cscore polviews1:Cscore 1.646217e+12 11
polviews2:Cscore polviews2:Cscore -4.070415e+12 12
polviews3:Cscore polviews3:Cscore -9.787047e+12 13
polviews4:Cscore polviews4:Cscore -1.550368e+13 14
polviews5:Cscore polviews5:Cscore -2.122031e+13 15
polviews6:Cscore polviews6:Cscore -2.693694e+13 16
polviews7:Cscore polviews7:Cscore -3.265357e+13 17
fefam1:Rscore fefam1:Rscore -1.714990e+13 18
fefam2:Rscore fefam2:Rscore -1.143326e+13 19
fefam3:Rscore fefam3:Rscore -5.716632e+12 20
fefam4:Rscore fefam4:Rscore NA 21制約を課すのは11番目,17番目,18番目の係数であり,これらを0にする.対象となる係数はconstrain = c(11,17,18)で指定し,制約はconstrainTo = c(0, 0, 0)とする.あとは同じである.
# polviews1:Cscore(11) = polviews7:Cscore(17) = fefam1:Rscore(18) = 0
RplusC <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
constrain = c(11, 17, 18),
constrainTo = c(0, 0, 0),
family = poisson,
data = _,
tolerance = 1e-12)
# 結果
summary(RplusC)
Call:
gnm(formula = Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
constrain = c(11, 17, 18), constrainTo = c(0, 0, 0), family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07536 -0.33353 0.01859 0.37548 1.05912
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69896 0.14301 25.866 < 2e-16 ***
polviews2 1.06075 0.12467 8.509 < 2e-16 ***
polviews3 0.76041 0.13412 5.670 1.43e-08 ***
polviews4 1.61203 0.15170 10.626 < 2e-16 ***
polviews5 0.37332 0.18884 1.977 0.048049 *
polviews6 0.02433 0.22727 0.107 0.914750
polviews7 -2.01888 0.30512 -6.617 3.67e-11 ***
fefam2 1.00654 0.09822 10.248 < 2e-16 ***
fefam3 0.65193 0.17688 3.686 0.000228 ***
fefam4 -0.40872 0.26352 -1.551 0.120895
polviews1:Cscore 0.00000 NA NA NA
polviews2:Cscore -0.08578 0.11437 -0.750 0.453211
polviews3:Cscore -0.15923 0.10585 -1.504 0.132498
polviews4:Cscore -0.12164 0.09246 -1.316 0.188309
polviews5:Cscore -0.22243 0.10510 -2.116 0.034309 *
polviews6:Cscore -0.09452 0.11454 -0.825 0.409232
polviews7:Cscore 0.00000 NA NA NA
fefam1:Rscore 0.00000 NA NA NA
fefam2:Rscore 0.27936 0.04372 6.389 1.67e-10 ***
fefam3:Rscore 0.48417 0.06239 7.761 < 2e-16 ***
fefam4:Rscore 0.58586 0.08655 6.769 1.30e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 7.6783 on 10 degrees of freedom
AIC: 215.03
Number of iterations: 4# モデル適合度
model.summary(RplusC)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RplusC 10 7.68 -73.8 1.77 0.66011番目,18番目,21番目の係数を0にして推定する.
# polviews1:Cscore(11) = polviews7:Cscore(17) = fefam1:Rscore(18) = 0
RplusC_2 <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
constrain = c(11, 18, 21),
constrainTo = c(0, 0, 0),
family = poisson,
data = _,
tolerance = 1e-12)
# 結果
summary(RplusC_2)
Call:
gnm(formula = Freq ~ polviews + fefam + Cscore:polviews + Rscore:fefam,
constrain = c(11, 18, 21), constrainTo = c(0, 0, 0), family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07536 -0.33353 0.01859 0.37548 1.05912
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69896 0.14301 25.866 < 2e-16 ***
polviews2 1.35368 0.13397 10.104 < 2e-16 ***
polviews3 1.34627 0.13954 9.648 < 2e-16 ***
polviews4 2.49082 0.14246 17.485 < 2e-16 ***
polviews5 1.54505 0.15938 9.694 < 2e-16 ***
polviews6 1.48899 0.17487 8.515 < 2e-16 ***
polviews7 -0.26129 0.21592 -1.210 0.226224
fefam2 0.42068 0.12573 3.346 0.000820 ***
fefam3 -0.51980 0.23987 -2.167 0.030233 *
fefam4 -2.16632 0.36822 -5.883 4.03e-09 ***
polviews1:Cscore 0.00000 NA NA NA
polviews2:Cscore 0.10951 0.12956 0.845 0.397978
polviews3:Cscore 0.23134 0.13130 1.762 0.078073 .
polviews4:Cscore 0.46422 0.12511 3.711 0.000207 ***
polviews5:Cscore 0.55872 0.13347 4.186 2.84e-05 ***
polviews6:Cscore 0.88192 0.13507 6.529 6.61e-11 ***
polviews7:Cscore 1.17173 0.17310 6.769 1.30e-11 ***
fefam1:Rscore 0.00000 NA NA NA
fefam2:Rscore 0.08407 0.03224 2.607 0.009124 **
fefam3:Rscore 0.09360 0.03861 2.424 0.015346 *
fefam4:Rscore 0.00000 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 7.6783 on 10 degrees of freedom
AIC: 215.03
Number of iterations: 4# モデル適合度
model.summary(RplusC_2)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RplusC_2 10 7.68 -73.8 1.77 0.660Rscore:Cscoreを含めて推定すれば,制約は自動的に課されており(polviewsの1番目と7番目,fefamの1 番目と4番目),特に指定する必要はない.
# 5. R+C: Row and Column Effect Model (Alternative)
RplusCalt <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Rscore:Cscore + Cscore:polviews + Rscore:fefam,
family = poisson,
data = _,
tolerance = 1e-12)
# 結果
summary(RplusCalt)
Call:
gnm(formula = Freq ~ polviews + fefam + Rscore:Cscore + Cscore:polviews +
Rscore:fefam, family = poisson, data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07536 -0.33353 0.01859 0.37548 1.05912
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.82017 0.13999 20.145 < 2e-16 ***
polviews2 1.35368 0.13397 10.104 < 2e-16 ***
polviews3 1.34627 0.13954 9.648 < 2e-16 ***
polviews4 2.49082 0.14246 17.485 < 2e-16 ***
polviews5 1.54505 0.15938 9.694 < 2e-16 ***
polviews6 1.48899 0.17487 8.515 < 2e-16 ***
polviews7 -0.26129 0.21592 -1.210 0.226224
fefam2 1.00654 0.09822 10.248 < 2e-16 ***
fefam3 0.65193 0.17688 3.686 0.000228 ***
fefam4 -0.40872 0.26352 -1.551 0.120895
Rscore:Cscore 0.19529 0.02885 6.769 1.3e-11 ***
polviews2:Cscore -0.08578 0.11437 -0.750 0.453211
polviews3:Cscore -0.15923 0.10585 -1.504 0.132498
polviews4:Cscore -0.12164 0.09246 -1.316 0.188309
polviews5:Cscore -0.22243 0.10510 -2.116 0.034309 *
polviews6:Cscore -0.09452 0.11454 -0.825 0.409232
polviews7:Cscore 0.00000 NA NA NA
fefam2:Rscore 0.08407 0.03224 2.607 0.009124 **
fefam3:Rscore 0.09360 0.03861 2.424 0.015346 *
fefam4:Rscore 0.00000 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 7.6783 on 10 degrees of freedom
AIC: 215.03
Number of iterations: 5# モデル適合度
model.summary(RplusCalt)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RplusCalt 10 7.68 -73.8 1.77 0.6602.6 行・列効果モデル(\(RC(1)\))
RC(1)についてはMult(1,polviews,fefam)を含んだモデルで推定する.結果をみると係数は表示されているものの,標準誤差はNAとなっている.
# 6. RC: RC(1) model
RC.un <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Mult(1,polviews,fefam),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations...............................
Done# 結果
summary(RC.un)
Call:
gnm(formula = Freq ~ polviews + fefam + Mult(1, polviews, fefam),
family = poisson, data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07428 -0.27239 0.03038 0.36792 1.03721
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.905187 NA NA NA
polviews2 1.391132 NA NA NA
polviews3 1.428513 NA NA NA
polviews4 2.589182 NA NA NA
polviews5 1.689091 NA NA NA
polviews6 1.630727 NA NA NA
polviews7 -0.107877 NA NA NA
fefam2 0.884908 NA NA NA
fefam3 0.406631 NA NA NA
fefam4 -0.776661 NA NA NA
Mult(., polviews, fefam). -4.336642 NA NA NA
Mult(1, ., fefam).polviews1 -0.452800 NA NA NA
Mult(1, ., fefam).polviews2 -0.349163 NA NA NA
Mult(1, ., fefam).polviews3 -0.210762 NA NA NA
Mult(1, ., fefam).polviews4 0.002778 NA NA NA
Mult(1, ., fefam).polviews5 0.094614 NA NA NA
Mult(1, ., fefam).polviews6 0.394937 NA NA NA
Mult(1, ., fefam).polviews7 0.651650 NA NA NA
Mult(1, polviews, .).fefam1 0.392229 NA NA NA
Mult(1, polviews, .).fefam2 0.052840 NA NA NA
Mult(1, polviews, .).fefam3 -0.211715 NA NA NA
Mult(1, polviews, .).fefam4 -0.337213 NA NA NA
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 8.0718 on 10 degrees of freedom
AIC: 215.43
Number of iterations: 31# モデル適合度
model.summary(RC.un)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC.un 10 8.07 -73.4 1.77 0.622まずは「重みづけのないまたは単位標準化した解」を求める.scaleWeights = "unit"とする.RC.unから.polviewsのある変数をpickCoef(RC.un, "[.]polviews")によって取り出す.
# mu[i], i = 1 to 7
mu <- getContrasts(RC.un, pickCoef(RC.un,
"[.]polviews"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
# 値の方向を揃える
if (mu$qvframe[1,1] > 0 ) {
mu$qvframe[,1] <- -1 * mu$qvframe[,1]
}
# 合計が0,2乗和が1となっていること確認する.
list("和" = sum(mu$qvframe[,1]),
"2乗和" = sum(mu$qvframe[,1]^2))$和
[1] 2.220446e-16
$`2乗和`
[1] 1# nu[j], j = 1 to 4
nu <- getContrasts(RC.un, pickCoef(RC.un, "[.]fefam"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
# 値の方向を揃える
if (nu$qvframe[1,1] > 0 ) {
nu$qvframe[,1] <- -1 * nu$qvframe[,1]
}
# 合計が0,2乗和が1となっていること確認する.
list("和" = sum(nu$qvframe[,1]),
"2乗和" = sum(nu$qvframe[,1]^2))$和
[1] -2.220446e-16
$`2乗和`
[1] 1# muの1番目と7番目,nuの1番目と4番目の値を取り出し保存する.
con <- c(mu$qvframe[,1][c(1,7)],
nu$qvframe[,1][c(1,4)])#保存した値で制約を課した上で,再推定する.
set.seed(1234)
RC <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Mult(1,polviews,fefam),
constrain = c(12,18,19,22),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations........................
DoneDeviance is not finite 警告メッセージ: Algorithm failed - no model could be estimatedと表示されたらもう一度推定する.set.seedの値をいくつか変えて実行するのがよい.
表2.5Eの値と一致しているのかを確認する.
# 結果
summary(RC)
Call:
gnm(formula = Freq ~ polviews + fefam + Mult(1, polviews, fefam),
constrain = c(12, 18, 19, 22), constrainTo = con, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07428 -0.27239 0.03038 0.36792 1.03721
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.82020 0.14578 19.346 < 2e-16 ***
polviews2 1.40280 0.12442 11.275 < 2e-16 ***
polviews3 1.45577 0.12746 11.421 < 2e-16 ***
polviews4 2.64048 0.13143 20.090 < 2e-16 ***
polviews5 1.75073 0.14175 12.351 < 2e-16 ***
polviews6 1.72618 0.16727 10.320 < 2e-16 ***
polviews7 0.01648 0.21938 0.075 0.940107
fefam2 0.91251 0.12222 7.466 8.25e-14 ***
fefam3 0.45574 0.20388 2.235 0.025396 *
fefam4 -0.71735 0.24913 -2.879 0.003985 **
Mult(., polviews, fefam). 2.37331 0.34813 6.817 9.27e-12 ***
Mult(1, ., fefam).polviews1 -0.48165 NA NA NA
Mult(1, ., fefam).polviews2 -0.37580 0.10049 -3.740 0.000184 ***
Mult(1, ., fefam).polviews3 -0.23443 0.09461 -2.478 0.013216 *
Mult(1, ., fefam).polviews4 -0.01632 0.08366 -0.195 0.845376
Mult(1, ., fefam).polviews5 0.07749 0.09263 0.837 0.402872
Mult(1, ., fefam).polviews6 0.38425 0.10926 3.517 0.000437 ***
Mult(1, ., fefam).polviews7 0.64646 NA NA NA
Mult(1, polviews, .).fefam1 -0.74812 NA NA NA
Mult(1, polviews, .).fefam2 -0.14098 0.07469 -1.888 0.059090 .
Mult(1, polviews, .).fefam3 0.33229 0.09162 3.627 0.000287 ***
Mult(1, polviews, .).fefam4 0.55680 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 8.0718 on 10 degrees of freedom
AIC: 215.43
Number of iterations: 24先ほどの単位標準化した解と推定の結果が一致しているのかを確認する.
# 指定したmuとnuの値と結果が一致しているかを確認
list(mu = mu, nu = nu)$mu
Estimate Std. Error
Mult(1, ., fefam).polviews1 -0.48165420 0.06776575
Mult(1, ., fefam).polviews2 -0.37579722 0.05016783
Mult(1, ., fefam).polviews3 -0.23443020 0.04842778
Mult(1, ., fefam).polviews4 -0.01631519 0.03689088
Mult(1, ., fefam).polviews5 0.07748893 0.04931050
Mult(1, ., fefam).polviews6 0.38424697 0.06009815
Mult(1, ., fefam).polviews7 0.64646091 0.06145462
$nu
Estimate Std. Error
Mult(1, polviews, .).fefam1 -0.7481178 0.02662158
Mult(1, polviews, .).fefam2 -0.1409760 0.04671343
Mult(1, polviews, .).fefam3 0.3322937 0.05164241
Mult(1, polviews, .).fefam4 0.5568002 0.04821776和が0,2乗和が1となっていることを確認
sum(mu$qvframe[,1])[1] 2.220446e-16sum(mu$qvframe[,1]^2)[1] 1sum(nu$qvframe[,1])[1] -2.220446e-16sum(nu$qvframe[,1]^2)[1] 1適合度は変化していない.
# モデル適合度
model.summary(RC.un)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC.un 10 8.07 -73.4 1.77 0.622model.summary(RC)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC 10 8.07 -73.4 1.77 0.6222.7 周辺重みづけ
# 行の周辺確率
rp <- prop.table(apply(tab_2.3A, 1, sum, na.rm = TRUE))
rp Strongly liberal Liberal Slightly liberal
0.03227682 0.12387322 0.12300087
Moderate Slightly conservative Conservative
0.38092469 0.15498691 0.15469613
Strongly conservative
0.03024135 sum(rp)[1] 1# 列の周辺確率
cp <- prop.table(apply(tab_2.3A, 2, sum, na.rm = TRUE))
cpStrongly Disagree Disagree Agree Strongly agree
0.19220704 0.43617331 0.28118639 0.09043327 sum(cp)[1] 1# mu[i], i = 1 to 7
mu <- getContrasts(RC.un, pickCoef(RC.un,
"[.]polviews"),
ref = rp,
scaleRef = rp,
scaleWeights = rp)
# 値の方向を揃える
if (mu$qvframe[1,1] > 0 ) {
mu$qvframe[,1] <- -1 * mu$qvframe[,1]
}
# nu[j], j = 1 to 4
nu <- getContrasts(RC.un, pickCoef(RC.un, "[.]fefam"),
ref = cp,
scaleRef = cp,
scaleWeights = cp)
# 値の方向を揃える
if (nu$qvframe[1,1] > 0 ) {
nu$qvframe[,1] <- -1 * nu$qvframe[,1]
}
# muの1番目と7番目,nuの1番目と4番目の値を取り出し保存する.
con <- c(mu$qvframe[,1][c(1,7)],
nu$qvframe[,1][c(1,4)])#保存した値で制約を課した上で,再推定する.
set.seed(1234)
RC_mw <- freq_tab_2.3A |>
gnm(Freq ~ polviews + fefam + Mult(1,polviews,fefam),
constrain = c(12,18,19,22),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations...........................................
Done# 結果
summary(RC_mw)
Call:
gnm(formula = Freq ~ polviews + fefam + Mult(1, polviews, fefam),
constrain = c(12, 18, 19, 22), constrainTo = con, family = poisson,
data = freq_tab_2.3A, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.07428 -0.27239 0.03038 0.36792 1.03721
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.90051 0.14144 20.507 < 2e-16 ***
polviews2 1.38735 0.11722 11.835 < 2e-16 ***
polviews3 1.41969 0.12024 11.807 < 2e-16 ***
polviews4 2.57257 0.12376 20.787 < 2e-16 ***
polviews5 1.66913 0.13414 12.443 < 2e-16 ***
polviews6 1.59981 0.16013 9.991 < 2e-16 ***
polviews7 -0.14816 0.21832 -0.679 0.497376
fefam2 0.90365 0.12173 7.423 1.14e-13 ***
fefam3 0.43998 0.20350 2.162 0.030615 *
fefam4 -0.73638 0.24896 -2.958 0.003098 **
Mult(., polviews, fefam). 0.25673 0.03766 6.817 9.27e-12 ***
Mult(1, ., fefam).polviews1 -1.82062 NA NA NA
Mult(1, ., fefam).polviews2 -1.41532 0.38476 -3.678 0.000235 ***
Mult(1, ., fefam).polviews3 -0.87405 0.36224 -2.413 0.015825 *
Mult(1, ., fefam).polviews4 -0.03893 0.32031 -0.122 0.903253
Mult(1, ., fefam).polviews5 0.32022 0.35468 0.903 0.366604
Mult(1, ., fefam).polviews6 1.49474 0.41835 3.573 0.000353 ***
Mult(1, ., fefam).polviews7 2.49870 NA NA NA
Mult(1, polviews, .).fefam1 -1.65778 NA NA NA
Mult(1, polviews, .).fefam2 -0.19190 0.18033 -1.064 0.287244
Mult(1, polviews, .).fefam3 0.95076 0.22120 4.298 1.72e-05 ***
Mult(1, polviews, .).fefam4 1.49281 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 8.0718 on 10 degrees of freedom
AIC: 215.43
Number of iterations: 43内的連関パラメータ\(\phi\)が0.25673となっている.場合によっては符号が逆となる.
適合度は変化していない.
# モデル適合度
model.summary(RC.un)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC.un 10 8.07 -73.4 1.77 0.622model.summary(RC)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC 10 8.07 -73.4 1.77 0.622model.summary(RC_mw)# A tibble: 1 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 RC_mw 10 8.07 -73.4 1.77 0.6222.8 表2.4A
表2.4Aを再現する.
models <- list()
models[[1]] <- model.summary(O)
models[[2]] <- model.summary(U)
models[[3]] <- model.summary(R)
models[[4]] <- model.summary(C)
models[[5]] <- model.summary(RplusC)
models[[6]] <- model.summary(RC)
models |> bind_rows() |> kable(digit = 3)| Model Description | df | L2 | BIC | Delta | p |
|---|---|---|---|---|---|
| O | 18 | 211.695 | 65.122 | 8.092 | 0.000 |
| U | 17 | 20.125 | -118.305 | 2.766 | 0.268 |
| R | 12 | 15.906 | -81.809 | 2.466 | 0.196 |
| C | 15 | 14.237 | -107.907 | 2.321 | 0.508 |
| RplusC | 10 | 7.678 | -73.751 | 1.772 | 0.660 |
| RC | 10 | 8.072 | -73.358 | 1.767 | 0.622 |
2.9 表2.4B
モデルの比較のための関数を作成する.引数は2つであり,1つめのモデルと2つめのモデルの比較を行う.2つめが指定されていなければ比較ではなくそのモデルの適合度を示す.
model_comparison <- function(x, y = 0) {
models |>
bind_rows() |>
dplyr::summarise(`Model Used` =
ifelse(y == 0,
paste0(x),
paste0(x,"-",y)),
df = ifelse(y == 0,
df[x],
df[x] - df[y]),
L2 = ifelse(y == 0,
L2[x],
L2[x] - L2[y]))
}表2.4Bは次のように再現できる.
# Table 2.4 Panel B
bind_rows(model_comparison(1,2),
model_comparison(2,6),
model_comparison(6),
model_comparison(1)) |> kable(digit = 3)| Model Used | df | L2 |
|---|---|---|
| 1-2 | 1 | 191.571 |
| 2-6 | 7 | 12.053 |
| 6 | 10 | 8.072 |
| 1 | 18 | 211.695 |
表2.4Cも再現できる.
# Table 2.4 Panel C
bind_rows(model_comparison(2,4),
model_comparison(4,6),
model_comparison(2,6)) |> kable(digit = 3)| Model Used | df | L2 |
|---|---|---|
| 2-4 | 2 | 5.887 |
| 4-6 | 5 | 6.165 |
| 2-6 | 7 | 12.053 |
2.10 表2.5A
係数を取り出して表2.5Aを再現する.
summary(U)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore:Cscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Rscore:Cscore 0.2021125 0.01519706 13.29945 2.331718e-402.11 表2.5B
省略された係数について,標準誤差を求める方法は次の通り.
# Table 2.5 Panel B
summary(R)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl(":Cscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 polviews1:Cscore -0.558726563 0.10766840 -5.1893275 2.110549e-07
2 polviews2:Cscore -0.405075736 0.05914888 -6.8484091 7.467575e-12
3 polviews3:Cscore -0.248458921 0.05774110 -4.3029822 1.685144e-05
4 polviews4:Cscore 0.008763861 0.03970853 0.2207048 8.253223e-01
5 polviews5:Cscore 0.112245001 0.05128383 2.1887016 2.861853e-02
6 polviews6:Cscore 0.419078627 0.05143368 8.1479420 3.701697e-16# polviews7:Cscoreを求める
mycontrast <- numeric(length(coef(R)))
terms <- pickCoef(R,"[:]Cscore")
mycontrast[terms] <- rep(-1,6)
mycontrast <- cbind(mycontrast)
colnames(mycontrast) <- "polviews7:Cscore"
gnm::se(R, mycontrast) Estimate Std. Error
polviews7:Cscore 0.6721737 0.10032112.12 表2.5B(他の正規化)
# Table 2.5 Panel B Alternative
summary(Ralt)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl(":Cscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 polviews2:Cscore 0.1536508 0.1361941 1.128176 2.592458e-01
2 polviews3:Cscore 0.3102676 0.1356609 2.287082 2.219102e-02
3 polviews4:Cscore 0.5674904 0.1267654 4.476699 7.580590e-06
4 polviews5:Cscore 0.6709716 0.1326215 5.059297 4.208051e-07
5 polviews6:Cscore 0.9778052 0.1331060 7.346062 2.041319e-13
6 polviews7:Cscore 1.2309003 0.1678130 7.334954 2.217982e-132.13 表2.5C
同様に列効果の最後のカテゴリの推定値と標準誤差を求める.
# Table 2.5 Panel C
summary(C)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl(":Rscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 fefam1:Rscore -0.32183233 0.02601065 -12.373099 3.654449e-35
2 fefam2:Rscore -0.06518238 0.02012977 -3.238109 1.203247e-03
3 fefam3:Rscore 0.13740293 0.02281996 6.021174 1.731567e-09# fefam4:Rscoreを求める
mycontrast <- numeric(length(coef(C)))
terms <- pickCoef(C,"[:]Rscore")
mycontrast[terms] <- rep(-1,3)
mycontrast <- cbind(mycontrast)
colnames(mycontrast) <- "fefam4:Rscore"
gnm::se(C, mycontrast) Estimate Std. Error
fefam4:Rscore 0.2496118 0.034296972.14 表2.5C(他の正規化)
1つ目のカテゴリの値を0とした正規化の場合は次のようになる.
# Table 2.5 Panel C Alternative
summary(Calt)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl(":Rscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 fefam2:Rscore 0.2566499 0.03458604 7.420624 1.165702e-13
2 fefam3:Rscore 0.4592353 0.03850703 11.926012 8.662502e-33
3 fefam4:Rscore 0.5714441 0.05297192 10.787680 3.935998e-272.15 表2.5D
# Table 2.5 Panel D
summary(RplusC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 polviews1:Cscore 0.00000000 NA NA NA
2 polviews2:Cscore -0.08578207 0.11436513 -0.7500719 4.532114e-01
3 polviews3:Cscore -0.15923097 0.10584890 -1.5043233 1.324981e-01
4 polviews4:Cscore -0.12164181 0.09246130 -1.3155970 1.883093e-01
5 polviews5:Cscore -0.22242867 0.10509647 -2.1164238 3.430878e-02
6 polviews6:Cscore -0.09452143 0.11453734 -0.8252455 4.092322e-01
7 polviews7:Cscore 0.00000000 NA NA NA
8 fefam1:Rscore 0.00000000 NA NA NA
9 fefam2:Rscore 0.27935717 0.04372418 6.3890770 1.668900e-10
10 fefam3:Rscore 0.48417258 0.06238681 7.7608170 8.438398e-15
11 fefam4:Rscore 0.58586364 0.08654948 6.7691179 1.295700e-112.16 表2.5D(他の正規化)
summary(RplusCalt)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Rscore:Cscore 0.19528788 0.02884983 6.7691178 1.295700e-11
2 polviews2:Cscore -0.08578207 0.11436513 -0.7500719 4.532114e-01
3 polviews3:Cscore -0.15923097 0.10584890 -1.5043233 1.324981e-01
4 polviews4:Cscore -0.12164181 0.09246130 -1.3155970 1.883093e-01
5 polviews5:Cscore -0.22242867 0.10509647 -2.1164238 3.430878e-02
6 polviews6:Cscore -0.09452143 0.11453734 -0.8252455 4.092322e-01
7 polviews7:Cscore 0.00000000 NA NA NA
8 fefam2:Rscore 0.08406929 0.03224287 2.6073757 9.123919e-03
9 fefam3:Rscore 0.09359682 0.03861067 2.4241178 1.534563e-02
10 fefam4:Rscore 0.00000000 NA NA NA2.17 表2.5E
summary(RC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Mult", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Mult(., polviews, fefam). 2.37330693 0.34812532 6.8173924 9.270782e-12
2 Mult(1, ., fefam).polviews1 -0.48165420 NA NA NA
3 Mult(1, ., fefam).polviews2 -0.37579722 0.10049018 -3.7396411 1.842832e-04
4 Mult(1, ., fefam).polviews3 -0.23443020 0.09460850 -2.4778980 1.321589e-02
5 Mult(1, ., fefam).polviews4 -0.01631519 0.08365831 -0.1950217 8.453760e-01
6 Mult(1, ., fefam).polviews5 0.07748893 0.09263438 0.8365030 4.028720e-01
7 Mult(1, ., fefam).polviews6 0.38424697 0.10926427 3.5166753 4.369880e-04
8 Mult(1, ., fefam).polviews7 0.64646091 NA NA NA
9 Mult(1, polviews, .).fefam1 -0.74811781 NA NA NA
10 Mult(1, polviews, .).fefam2 -0.14097601 0.07468829 -1.8875250 5.908974e-02
11 Mult(1, polviews, .).fefam3 0.33229365 0.09161751 3.6269668 2.867702e-04
12 Mult(1, polviews, .).fefam4 0.55680017 NA NA NA2.18 logmultパッケージの利用
logmultはgnmをベースとしてRCモデルを簡単に実行できる関数である.
まずはlogmultパッケージのanoasで連関分析を行う.データはtableなのでtab_2.3Aを使用する.
anoasは独立モデル,RC(1),RC(2),RC(3),…と次元がmin(nrow(tab) - 1, ncol(tab) - 1)までのRCモデルを推定する.RC(1)の結果は表2.4Aと一致している.
anoas(tab_2.3A)Fitting independence model...
Fitting model with 1 dimension...
Initialising
Running start-up iterations..
Running main iterations...................
Done
Fitting model with 2 dimensions...
Initialising
Running start-up iterations..
Running main iterations..........................
Done
Fitting model with 3 dimensions...
Initialising
Running start-up iterations..
Running main iterations...
Done Res. Df Res. Dev Dev./Indep. (%) Dissim. (%)
Indep. 18 211.69508974175693 100.000000000000000 8.09171028965
RC(1) 10 8.07181892815000 3.812945750417107 1.76730792765
RC(2) 4 1.36909098846095 0.646727796157711 0.49639212377
RC(3) 0 -0.00000000000001 -0.000000000000005 0.00000000004
BIC AIC Dev. Df
Indep. 65.12224155397615 175.69508974175693 NA NA
RC(1) -73.35754117617265 -11.92818107185000 -204 -8
RC(2) -31.20265305326811 -6.63090901153905 -7 -6
RC(3) -0.00000000000001 -0.00000000000001 -1 -4表2.5Eの推定値(RC(1))はrcを用いて次のように再現できる.nd = 1で次元を1としている.標準誤差を求める上で,ブートストラップ法を用いている.結果には\(\gamma=\delta=1/2\)の場合の係数(Adjusted)が示されている.
rc_fit <- rc(tab_2.3A,
nd = 1,
se = "bootstrap",
weighting = "none",
nreplicates = 100,
ncpus = getOption("boot.ncpus")
)Initialising
Running start-up iterations..
Running main iterations...........
Done
Computing bootstrap standard errors....summary(rc_fit, weighting = "none")Call:
rc(tab = tab_2.3A, nd = 1, weighting = "none", se = "bootstrap",
nreplicates = 100, ncpus = getOption("boot.ncpus"))
Deviance Residuals:
Min 1Q Median 3Q Max
-1.0743 -0.2724 0.0304 0.3679 1.0372
Association coefficients:
Normalized Adjusted Std. error
Dim1 2.373307 NA 0.2735
Dim1:polviewsStrongly liberal 0.481654 0.742014 0.0732
Dim1:polviewsLiberal 0.375797 0.578936 0.0505
Dim1:polviewsSlightly liberal 0.234430 0.361152 0.0544
Dim1:polviewsModerate 0.016315 0.025134 0.0326
Dim1:polviewsSlightly conservative -0.077489 -0.119376 0.0492
Dim1:polviewsConservative -0.384247 -0.591953 0.0596
Dim1:polviewsStrongly conservative -0.646461 -0.995908 0.0621
Dim1:fefamStrongly Disagree 0.748118 1.152516 0.0252
Dim1:fefamDisagree 0.140976 0.217181 0.0470
Dim1:fefamAgree -0.332294 -0.511916 0.0583
Dim1:fefamStrongly agree -0.556800 -0.857781 0.0489
Pr(>|z|)
Dim1 < 2.2e-16 ***
Dim1:polviewsStrongly liberal 4.834e-11 ***
Dim1:polviewsLiberal 1.003e-13 ***
Dim1:polviewsSlightly liberal 1.609e-05 ***
Dim1:polviewsModerate 0.616651
Dim1:polviewsSlightly conservative 0.114925
Dim1:polviewsConservative 1.121e-10 ***
Dim1:polviewsStrongly conservative < 2.2e-16 ***
Dim1:fefamStrongly Disagree < 2.2e-16 ***
Dim1:fefamDisagree 0.002683 **
Dim1:fefamAgree 1.214e-08 ***
Dim1:fefamStrongly agree < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Normalization weights: none
Deviance: 8.071819
Pearson chi-squared: 8.168769
Dissimilarity index: 1.767308%
Residual df: 10
BIC: -73.35754
AIC: -11.92818周辺重みづけを用いたい場合は`weighting = “marginal”とする.
rc_fit_wm <- rc(tab_2.3A,
nd = 1,
se = "bootstrap",
weighting = "marginal",
nreplicates = 100,
ncpus = getOption("boot.ncpus")
)Initialising
Running start-up iterations..
Running main iterations.............
Done
Computing bootstrap standard errors...
.summary(rc_fit_wm)Call:
rc(tab = tab_2.3A, nd = 1, weighting = "marginal", se = "bootstrap",
nreplicates = 100, ncpus = getOption("boot.ncpus"))
Deviance Residuals:
Min 1Q Median 3Q Max
-1.0743 -0.2724 0.0304 0.3679 1.0372
Association coefficients:
Normalized Adjusted Std. error
Dim1 0.256734 NA 0.0185
Dim1:polviewsStrongly liberal 1.820624 0.922490 0.3333
Dim1:polviewsLiberal 1.415319 0.717126 0.1601
Dim1:polviewsSlightly liberal 0.874053 0.442873 0.1882
Dim1:polviewsModerate 0.038935 0.019728 0.0944
Dim1:polviewsSlightly conservative -0.320222 -0.162253 0.1777
Dim1:polviewsConservative -1.494737 -0.757366 0.1303
Dim1:polviewsStrongly conservative -2.498701 -1.266064 0.4518
Dim1:fefamStrongly Disagree 1.657784 0.839980 0.0847
Dim1:fefamDisagree 0.191902 0.097234 0.0811
Dim1:fefamAgree -0.950760 -0.481739 0.0891
Dim1:fefamStrongly agree -1.492808 -0.756389 0.1960
Pr(>|z|)
Dim1 < 2.2e-16 ***
Dim1:polviewsStrongly liberal 4.701e-08 ***
Dim1:polviewsLiberal < 2.2e-16 ***
Dim1:polviewsSlightly liberal 3.393e-06 ***
Dim1:polviewsModerate 0.67992
Dim1:polviewsSlightly conservative 0.07150 .
Dim1:polviewsConservative < 2.2e-16 ***
Dim1:polviewsStrongly conservative 3.197e-08 ***
Dim1:fefamStrongly Disagree < 2.2e-16 ***
Dim1:fefamDisagree 0.01798 *
Dim1:fefamAgree < 2.2e-16 ***
Dim1:fefamStrongly agree 2.616e-14 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Normalization weights: marginal
Deviance: 8.071819
Pearson chi-squared: 8.168769
Dissimilarity index: 1.767308%
Residual df: 10
BIC: -73.35754
AIC: -11.92818これは先ほど求めた周辺重みづけの結果(内的連関パラメータが0.25673)と一致する.
2.19 表2.3B
# コントラストを確認
options("contrasts")$contrasts
factor ordered
"contr.treatment" "contr.treatment" # default
options(contrasts = c(factor = "contr.treatment",
ordered = "contr.poly"))anoasを用いるときにはのエラーを無くすために行列はラベルを用いない.
Freq <- c(518, 95, 6, 35, 5,
81, 67, 4, 49, 2,
452, 1003, 67, 630, 5,
71, 157, 37, 562, 12)
# データを表形式に変換
tab_2.3B <- matrix(Freq,
nrow = 4,
ncol = 5,
byrow = TRUE) |> as.table()
tab_2.3B A B C D E
A 518 95 6 35 5
B 81 67 4 49 2
C 452 1003 67 630 5
D 71 157 37 562 12# 度数,行変数,列変数からなる集計データを作成
Educ <- gl(n = 4, k = 5)
Occ <- gl(n = 5, k = 1, length = 20)
freq_tab_2.3B <- tibble(Freq, Educ, Occ)
freq_tab_2.3B# A tibble: 20 × 3
Freq Educ Occ
<dbl> <fct> <fct>
1 518 1 1
2 95 1 2
3 6 1 3
4 35 1 4
5 5 1 5
6 81 2 1
7 67 2 2
8 4 2 3
9 49 2 4
10 2 2 5
11 452 3 1
12 1003 3 2
13 67 3 3
14 630 3 4
15 5 3 5
16 71 4 1
17 157 4 2
18 37 4 3
19 562 4 4
20 12 4 5 # 行変数と列変数の整数値を作成
freq_tab_2.3B <- freq_tab_2.3B |>
mutate(Rscore = as.numeric(Educ),
Cscore = as.numeric(Occ))
freq_tab_2.3B# A tibble: 20 × 5
Freq Educ Occ Rscore Cscore
<dbl> <fct> <fct> <dbl> <dbl>
1 518 1 1 1 1
2 95 1 2 1 2
3 6 1 3 1 3
4 35 1 4 1 4
5 5 1 5 1 5
6 81 2 1 2 1
7 67 2 2 2 2
8 4 2 3 2 3
9 49 2 4 2 4
10 2 2 5 2 5
11 452 3 1 3 1
12 1003 3 2 3 2
13 67 3 3 3 3
14 630 3 4 3 4
15 5 3 5 3 5
16 71 4 1 4 1
17 157 4 2 4 2
18 37 4 3 4 3
19 562 4 4 4 4
20 12 4 5 4 5O <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ,
family = poisson,
data = _,
tolerance = 1e-12)
U <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore,
family = poisson,
data = _,
tolerance = 1e-12)
R <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Educ:Cscore,
family = poisson,
data = _,
tolerance = 1e-12)
C <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Occ:Rscore,
family = poisson,
data = _,
tolerance = 1e-12)
RplusC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Educ:Cscore +
Occ:Rscore,
constrain = c(12,16),
constrainTo = c(0,0),
family = poisson,
data = _,
tolerance = 1e-12)
RC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.........................................................
.............................
DoneUplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.........................................................
.
DoneRplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Mult(1, Educ, Occ),
constrain = c(9,12),
constrainTo = c(0,0),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.......................................
DoneCplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Occ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations......................................................
DoneRplusCplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Rscore:Occ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations...........
DoneRC2 <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
instances(Mult(1, Educ, Occ),2),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.....................
Done2.20 表2.6A
表2.6Aを再現する.
models <- list()
models[[1]] <- model.summary(O)
models[[2]] <- model.summary(U)
models[[3]] <- model.summary(R)
models[[4]] <- model.summary(C)
models[[5]] <- model.summary(RplusC)
models[[6]] <- model.summary(RC)
models[[7]] <- model.summary(UplusRC)
models[[8]] <- model.summary(RplusRC)
models[[9]] <- model.summary(CplusRC)
models[[10]] <- model.summary(RplusCplusRC)
models[[11]] <- model.summary(RC2)
models |> bind_rows()# A tibble: 11 × 6
`Model Description` df L2 BIC Delta p
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 O 12 1373. 1274. 23.9 8.44e-287
2 U 11 244. 153. 8.54 4.99e- 46
3 R 9 206. 132. 7.38 1.85e- 39
4 C 8 155. 89.3 7.47 1.48e- 29
5 RplusC 6 91.6 42.1 4.63 1.40e- 17
6 RC 6 125. 75.5 6.44 1.41e- 24
7 UplusRC 5 17.6 -23.7 1.52 3.49e- 3
8 RplusRC 4 6.94 -26.1 0.832 1.39e- 1
9 CplusRC 3 11.4 -13.4 1.01 9.72e- 3
10 RplusCplusRC 2 0.278 -16.2 0.0538 8.70e- 1
11 RC2 2 0.600 -15.9 0.0935 7.41e- 12.21 表2.6B
# Table 2.4 Panel B
bind_rows(model_comparison(1,6),
model_comparison(6,11),
model_comparison(11),
model_comparison(1))# A tibble: 4 × 3
`Model Used` df L2
<chr> <int> <dbl>
1 1-6 6 1248.
2 6-11 4 124.
3 11 2 0.600
4 1 12 1373. 2.22 表2.6C
# Table 2.4 Panel C
bind_rows(model_comparison(1,2),
model_comparison(2,6),
model_comparison(6,10),
model_comparison(10),
model_comparison(1))# A tibble: 5 × 3
`Model Used` df L2
<chr> <int> <dbl>
1 1-2 1 1129.
2 2-6 5 119.
3 6-10 4 125.
4 10 2 0.278
5 1 12 1373. 2.23 表2.7A
set.seed(1234)
UplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.........................................................
..............
Donesummary(UplusRC)
Call:
gnm(formula = Freq ~ Educ + Occ + Rscore:Cscore + Mult(1, Educ,
Occ), family = poisson, data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.0893 -0.5631 0.1321 0.7372 1.9761
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.49123 NA NA NA
Educ2 -2.07045 NA NA NA
Educ3 -1.00877 NA NA NA
Educ4 -3.55473 NA NA NA
Occ2 -1.06909 NA NA NA
Occ3 -5.17113 NA NA NA
Occ4 -4.53939 NA NA NA
Occ5 -10.91018 NA NA NA
Rscore:Cscore 0.55212 0.03429 16.1 <2e-16 ***
Mult(., Educ, Occ). 0.05379 NA NA NA
Mult(1, ., Occ).Educ1 57.38879 NA NA NA
Mult(1, ., Occ).Educ2 28.47707 NA NA NA
Mult(1, ., Occ).Educ3 -10.70009 NA NA NA
Mult(1, ., Occ).Educ4 9.22301 NA NA NA
Mult(1, Educ, .).Occ1 0.06067 NA NA NA
Mult(1, Educ, .).Occ2 -0.31188 NA NA NA
Mult(1, Educ, .).Occ3 0.01526 NA NA NA
Mult(1, Educ, .).Occ4 0.19408 NA NA NA
Mult(1, Educ, .).Occ5 1.34889 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 17.602 on 5 degrees of freedom
AIC: 163.98
Number of iterations: 71# 変数と係数と係数の順番を表示
pickCoef(UplusRC, "[.]Educ")Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ3
11 12 13
Mult(1, ., Occ).Educ4
14 pickCoef(UplusRC, "[.]Occ")Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ3
15 16 17
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ5
18 19 data.frame(var = names(UplusRC$coefficients),
estimate = UplusRC$coefficients) |>
mutate(estimate = estimate,
number = row_number()) var estimate number
(Intercept) (Intercept) 5.49123206 1
Educ2 Educ2 -2.07045034 2
Educ3 Educ3 -1.00877122 3
Educ4 Educ4 -3.55472593 4
Occ2 Occ2 -1.06909237 5
Occ3 Occ3 -5.17112951 6
Occ4 Occ4 -4.53939355 7
Occ5 Occ5 -10.91018443 8
Rscore:Cscore Rscore:Cscore 0.55211791 9
Mult(., Educ, Occ). Mult(., Educ, Occ). 0.05378691 10
Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ1 57.38878762 11
Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ2 28.47707090 12
Mult(1, ., Occ).Educ3 Mult(1, ., Occ).Educ3 -10.70009235 13
Mult(1, ., Occ).Educ4 Mult(1, ., Occ).Educ4 9.22300628 14
Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ1 0.06066883 15
Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ2 -0.31187524 16
Mult(1, Educ, .).Occ3 Mult(1, Educ, .).Occ3 0.01525644 17
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ4 0.19407628 18
Mult(1, Educ, .).Occ5 Mult(1, Educ, .).Occ5 1.34889132 19mu <- getContrasts(UplusRC,
pickCoef(UplusRC, "[.]Educ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
nu <- getContrasts(UplusRC,
pickCoef(UplusRC, "[.]Occ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
# 中心化制約と尺度化制約の確認
sum(mu$qvframe[,1]) |> round()[1] 0sum(mu$qvframe[,1]^2)[1] 1sum(nu$qvframe[,1]) |> round()[1] 0sum(nu$qvframe[,1]^2)[1] 1# 行スコアと列スコアの両端の値を固定する
con <- c(mu$qvframe[,1][c(1,4)],nu$qvframe[,1][c(1,5)])
set.seed(1234567)
UplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Cscore +
Mult(1, Educ, Occ),
constrain = c(11,14,15,19),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.........................................................
.........
Donesummary(UplusRC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore|Mult",
Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Rscore:Cscore 0.55211791 0.03429436 16.099379 2.576758e-58
2 Mult(., Educ, Occ). 3.43558976 0.61932837 5.547283 2.901428e-08
3 Mult(1, ., Occ).Educ1 0.72242916 NA NA NA
4 Mult(1, ., Occ).Educ2 0.14690561 0.13431003 1.093780 2.740515e-01
5 Mult(1, ., Occ).Educ3 -0.63296437 0.13149187 -4.813715 1.481501e-06
6 Mult(1, ., Occ).Educ4 -0.23637040 NA NA NA
7 Mult(1, Educ, .).Occ1 -0.15787324 NA NA NA
8 Mult(1, Educ, .).Occ2 -0.45087063 0.05888770 -7.656448 1.911463e-14
9 Mult(1, Educ, .).Occ3 -0.19358905 0.08174718 -2.368143 1.787760e-02
10 Mult(1, Educ, .).Occ4 -0.05295134 0.05110102 -1.036209 3.001047e-01
11 Mult(1, Educ, .).Occ5 0.85528425 NA NA NA2.24 表2.7B
RplusRC.un <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.............................
Donesummary(RplusRC.un)
Call:
gnm(formula = Freq ~ Educ + Occ + Cscore:Educ + Mult(1, Educ,
Occ), family = poisson, data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.96462 -0.24301 -0.05231 0.31330 1.21311
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.8043 NA NA NA
Educ2 -2.5496 NA NA NA
Educ3 -1.0924 NA NA NA
Educ4 -3.6305 NA NA NA
Occ2 1.0437 NA NA NA
Occ3 -0.7855 NA NA NA
Occ4 2.0809 NA NA NA
Occ5 -1.8534 NA NA NA
Educ1:Cscore -1.7432 NA NA NA
Educ2:Cscore -0.9182 NA NA NA
Educ3:Cscore -0.5398 NA NA NA
Educ4:Cscore 0.0000 NA NA NA
Mult(., Educ, Occ). -0.4213 NA NA NA
Mult(1, ., Occ).Educ1 -2.0586 NA NA NA
Mult(1, ., Occ).Educ2 -0.7258 NA NA NA
Mult(1, ., Occ).Educ3 0.5605 NA NA NA
Mult(1, ., Occ).Educ4 -0.2104 NA NA NA
Mult(1, Educ, .).Occ1 0.2200 NA NA NA
Mult(1, Educ, .).Occ2 -0.9616 NA NA NA
Mult(1, Educ, .).Occ3 0.1953 NA NA NA
Mult(1, Educ, .).Occ4 0.7768 NA NA NA
Mult(1, Educ, .).Occ5 4.8551 NA NA NA
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 6.9359 on 4 degrees of freedom
AIC: 155.31
Number of iterations: 29pickCoef(RplusRC.un, "[:]Cscore")Educ1:Cscore Educ2:Cscore Educ3:Cscore Educ4:Cscore
9 10 11 12 RplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Mult(1, Educ, Occ),
constrain = c(9,12),
constrainTo = c(0,0),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations........................................
Donesummary(RplusRC)
Call:
gnm(formula = Freq ~ Educ + Occ + Cscore:Educ + Mult(1, Educ,
Occ), constrain = c(9, 12), constrainTo = c(0, 0), family = poisson,
data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.96462 -0.24301 -0.05231 0.31330 1.21311
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 5.0338 NA NA NA
Educ2 -0.4417 NA NA NA
Educ3 3.0501 NA NA NA
Educ4 -0.7074 NA NA NA
Occ2 0.6767 NA NA NA
Occ3 -1.1329 NA NA NA
Occ4 1.6580 NA NA NA
Occ5 -1.7737 NA NA NA
Educ1:Cscore 0.0000 NA NA NA
Educ2:Cscore -0.4321 0.2210 -1.955 0.0506 .
Educ3:Cscore -1.2670 0.1931 -6.562 5.31e-11 ***
Educ4:Cscore 0.0000 NA NA NA
Mult(., Educ, Occ). -1.5191 NA NA NA
Mult(1, ., Occ).Educ1 4.6510 NA NA NA
Mult(1, ., Occ).Educ2 0.9307 NA NA NA
Mult(1, ., Occ).Educ3 -2.6602 NA NA NA
Mult(1, ., Occ).Educ4 -0.5081 NA NA NA
Mult(1, Educ, .).Occ1 -0.1724 NA NA NA
Mult(1, Educ, .).Occ2 0.1674 NA NA NA
Mult(1, Educ, .).Occ3 0.2749 NA NA NA
Mult(1, Educ, .).Occ4 0.4395 NA NA NA
Mult(1, Educ, .).Occ5 0.2568 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 6.9359 on 4 degrees of freedom
AIC: 155.31
Number of iterations: 40# 変数と係数と係数の順番を表示
pickCoef(RplusRC.un, "[.]Educ")Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ3
14 15 16
Mult(1, ., Occ).Educ4
17 pickCoef(RplusRC.un, "[.]Occ")Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ3
18 19 20
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ5
21 22 data.frame(var = names(RplusRC$coefficients),
estimate = RplusRC$coefficients) |>
mutate(estimate = estimate,
number = row_number()) var estimate number
(Intercept) (Intercept) 5.0338134 1
Educ2 Educ2 -0.4416984 2
Educ3 Educ3 3.0500999 3
Educ4 Educ4 -0.7074330 4
Occ2 Occ2 0.6766646 5
Occ3 Occ3 -1.1329222 6
Occ4 Occ4 1.6579720 7
Occ5 Occ5 -1.7736652 8
Educ1:Cscore Educ1:Cscore NA 9
Educ2:Cscore Educ2:Cscore -0.4320760 10
Educ3:Cscore Educ3:Cscore -1.2669500 11
Educ4:Cscore Educ4:Cscore NA 12
Mult(., Educ, Occ). Mult(., Educ, Occ). -1.5191478 13
Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ1 4.6509709 14
Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ2 0.9307366 15
Mult(1, ., Occ).Educ3 Mult(1, ., Occ).Educ3 -2.6601848 16
Mult(1, ., Occ).Educ4 Mult(1, ., Occ).Educ4 -0.5080538 17
Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ1 -0.1724067 18
Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ2 0.1674123 19
Mult(1, Educ, .).Occ3 Mult(1, Educ, .).Occ3 0.2748827 20
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ4 0.4395333 21
Mult(1, Educ, .).Occ5 Mult(1, Educ, .).Occ5 0.2567545 22mu <- getContrasts(RplusRC,
pickCoef(RplusRC, "[.]Educ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
nu <- getContrasts(RplusRC,
pickCoef(RplusRC, "[.]Occ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
con <- c(0,0,
mu$qvframe[,1][c(1,4)],
nu$qvframe[,1][c(1,5)])
RplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Mult(1, Educ, Occ),
constrain = c(9,12,14,17,18,22),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.....................................
Donesummary(RplusRC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore|Mult", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Educ1:Cscore 0.00000000 NA NA NA
2 Educ2:Cscore -0.43207600 0.2209849 -1.9552282 5.055614e-02
3 Educ3:Cscore -1.26695003 0.1930731 -6.5620238 5.308234e-11
4 Educ4:Cscore 0.00000000 NA NA NA
5 Mult(., Educ, Occ). -3.67046405 0.5474332 -6.7048620 2.015968e-11
6 Mult(1, ., Occ).Educ1 0.75983648 NA NA NA
7 Mult(1, ., Occ).Educ2 0.06145542 0.1367987 0.4492399 6.532586e-01
8 Mult(1, ., Occ).Educ3 -0.61265036 0.1325427 -4.6222852 3.795357e-06
9 Mult(1, ., Occ).Educ4 -0.20864153 NA NA NA
10 Mult(1, Educ, .).Occ1 -0.80614447 NA NA NA
11 Mult(1, Educ, .).Occ2 -0.05693272 0.1225191 -0.4646846 6.421573e-01
12 Mult(1, Educ, .).Occ3 0.18001127 0.1630841 1.1037941 2.696825e-01
13 Mult(1, Educ, .).Occ4 0.54302264 0.2004941 2.7084221 6.760398e-03
14 Mult(1, Educ, .).Occ5 0.14004328 NA NA NA2.25 表2.7C
Algorithm failed - no model could be estimatedとなったら再度推定すること.
set.seed(1234)
CplusRC.un <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Occ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations...................................................
Donesummary(CplusRC.un)
Call:
gnm(formula = Freq ~ Educ + Occ + Rscore:Occ + Mult(1, Educ,
Occ), family = poisson, data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.98938 -0.14103 -0.01486 0.18280 2.20453
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.10137 NA NA NA
Educ2 -0.60908 NA NA NA
Educ3 1.91190 NA NA NA
Educ4 0.89240 NA NA NA
Occ2 -1.92075 NA NA NA
Occ3 -5.71514 NA NA NA
Occ4 -4.14240 NA NA NA
Occ5 -6.62799 NA NA NA
Occ1:Rscore -0.95586 NA NA NA
Occ2:Rscore -0.14909 NA NA NA
Occ3:Rscore 0.31615 NA NA NA
Occ4:Rscore 0.57050 NA NA NA
Occ5:Rscore 0.00000 NA NA NA
Mult(., Educ, Occ). 0.66123 NA NA NA
Mult(1, ., Occ).Educ1 2.38686 NA NA NA
Mult(1, ., Occ).Educ2 0.76217 NA NA NA
Mult(1, ., Occ).Educ3 -1.41566 NA NA NA
Mult(1, ., Occ).Educ4 2.21619 NA NA NA
Mult(1, Educ, .).Occ1 0.05371 NA NA NA
Mult(1, Educ, .).Occ2 -0.28583 NA NA NA
Mult(1, Educ, .).Occ3 0.04603 NA NA NA
Mult(1, Educ, .).Occ4 0.13605 NA NA NA
Mult(1, Educ, .).Occ5 0.76573 NA NA NA
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 11.405 on 3 degrees of freedom
AIC: 161.78
Number of iterations: 51pickCoef(CplusRC.un, "[:]Rscore")Occ1:Rscore Occ2:Rscore Occ3:Rscore Occ4:Rscore Occ5:Rscore
9 10 11 12 13 CplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Occ +
Mult(1, Educ, Occ),
constrain = c(9,13),
constrainTo = c(0,0),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations..............................................
Donesummary(CplusRC)
Call:
gnm(formula = Freq ~ Educ + Occ + Rscore:Occ + Mult(1, Educ,
Occ), constrain = c(9, 13), constrainTo = c(0, 0), family = poisson,
data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.98938 -0.14103 -0.01486 0.18280 2.20453
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 6.20363 NA NA NA
Educ2 -1.63502 NA NA NA
Educ3 -0.14273 NA NA NA
Educ4 -2.16197 NA NA NA
Occ2 -2.71651 NA NA NA
Occ3 -5.73314 NA NA NA
Occ4 -3.94944 NA NA NA
Occ5 -4.95928 NA NA NA
Occ1:Rscore 0.00000 NA NA NA
Occ2:Rscore 1.26259 0.16970 7.440 1.00e-13 ***
Occ3:Rscore 1.28232 0.20937 6.125 9.08e-10 ***
Occ4:Rscore 1.41583 0.09054 15.638 < 2e-16 ***
Occ5:Rscore 0.00000 NA NA NA
Mult(., Educ, Occ). 0.19485 NA NA NA
Mult(1, ., Occ).Educ1 2.16357 NA NA NA
Mult(1, ., Occ).Educ2 3.16895 NA NA NA
Mult(1, ., Occ).Educ3 2.80310 NA NA NA
Mult(1, ., Occ).Educ4 16.83940 NA NA NA
Mult(1, Educ, .).Occ1 0.06320 NA NA NA
Mult(1, Educ, .).Occ2 -0.40161 NA NA NA
Mult(1, Educ, .).Occ3 0.05268 NA NA NA
Mult(1, Educ, .).Occ4 0.17592 NA NA NA
Mult(1, Educ, .).Occ5 1.03792 NA NA NA
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 11.405 on 3 degrees of freedom
AIC: 161.78
Number of iterations: 46summary(CplusRC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore|Mult", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Occ1:Rscore 0.00000000 NA NA NA
2 Occ2:Rscore 1.26259006 0.1696974 7.440245 1.004990e-13
3 Occ3:Rscore 1.28231939 0.2093667 6.124752 9.082487e-10
4 Occ4:Rscore 1.41582828 0.0905404 15.637531 4.040916e-55
5 Occ5:Rscore 0.00000000 NA NA NA
6 Mult(., Educ, Occ). 0.19484605 NA NA NA
7 Mult(1, ., Occ).Educ1 2.16357386 NA NA NA
8 Mult(1, ., Occ).Educ2 3.16895075 NA NA NA
9 Mult(1, ., Occ).Educ3 2.80310016 NA NA NA
10 Mult(1, ., Occ).Educ4 16.83939688 NA NA NA
11 Mult(1, Educ, .).Occ1 0.06320167 NA NA NA
12 Mult(1, Educ, .).Occ2 -0.40161169 NA NA NA
13 Mult(1, Educ, .).Occ3 0.05268391 NA NA NA
14 Mult(1, Educ, .).Occ4 0.17591506 NA NA NA
15 Mult(1, Educ, .).Occ5 1.03791723 NA NA NA# 変数と係数と係数の順番を表示
data.frame(var = names(CplusRC$coefficients),
estimate = CplusRC$coefficients) |>
mutate(estimate = estimate,
number = row_number()) var estimate number
(Intercept) (Intercept) 6.20363194 1
Educ2 Educ2 -1.63501732 2
Educ3 Educ3 -0.14273304 3
Educ4 Educ4 -2.16196522 4
Occ2 Occ2 -2.71650934 5
Occ3 Occ3 -5.73314338 6
Occ4 Occ4 -3.94943954 7
Occ5 Occ5 -4.95928306 8
Occ1:Rscore Occ1:Rscore NA 9
Occ2:Rscore Occ2:Rscore 1.26259006 10
Occ3:Rscore Occ3:Rscore 1.28231939 11
Occ4:Rscore Occ4:Rscore 1.41582828 12
Occ5:Rscore Occ5:Rscore NA 13
Mult(., Educ, Occ). Mult(., Educ, Occ). 0.19484605 14
Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ1 2.16357386 15
Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ2 3.16895075 16
Mult(1, ., Occ).Educ3 Mult(1, ., Occ).Educ3 2.80310016 17
Mult(1, ., Occ).Educ4 Mult(1, ., Occ).Educ4 16.83939688 18
Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ1 0.06320167 19
Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ2 -0.40161169 20
Mult(1, Educ, .).Occ3 Mult(1, Educ, .).Occ3 0.05268391 21
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ4 0.17591506 22
Mult(1, Educ, .).Occ5 Mult(1, Educ, .).Occ5 1.03791723 23mu <- getContrasts(CplusRC,
pickCoef(CplusRC, "[.]Educ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
nu <- getContrasts(CplusRC,
pickCoef(CplusRC, "[.]Occ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
con <- c(0,0,
mu$qvframe[,1][c(1,4)],
nu$qvframe[,1][c(1,5)])
CplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Rscore:Occ +
Mult(1, Educ, Occ),
constrain = c(9,13,15,18,19,23),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations...............................................
Donesummary(CplusRC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore|Mult", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Occ1:Rscore 0.000000000 NA NA NA
2 Occ2:Rscore 1.262590058 0.16969738 7.440245 1.004990e-13
3 Occ3:Rscore 1.282319390 0.20936674 6.124752 9.082487e-10
4 Occ4:Rscore 1.415828283 0.09054040 15.637531 4.040916e-55
5 Occ5:Rscore 0.000000000 NA NA NA
6 Mult(., Educ, Occ). 2.509132039 0.47337666 5.300498 1.154873e-07
7 Mult(1, ., Occ).Educ1 -0.332914652 NA NA NA
8 Mult(1, ., Occ).Educ2 -0.250882838 0.17043562 -1.472009 1.410183e-01
9 Mult(1, ., Occ).Educ3 -0.280733721 0.25875316 -1.084948 2.779447e-01
10 Mult(1, ., Occ).Educ4 0.864531211 NA NA NA
11 Mult(1, Educ, .).Occ1 -0.116510615 NA NA NA
12 Mult(1, Educ, .).Occ2 -0.558888360 0.15090381 -3.703607 2.125557e-04
13 Mult(1, Educ, .).Occ3 -0.126520705 0.12280113 -1.030289 3.028742e-01
14 Mult(1, Educ, .).Occ4 -0.009237675 0.06533009 -0.141400 8.875539e-01
15 Mult(1, Educ, .).Occ5 0.811157355 NA NA NA2.26 表2.7D
まずは行効果と列効果のパラメータに対して0という制約を課し,その上で推定した行スコアと列スコアを正規化し,再度推定する.
RplusCplusRC.un <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Rscore:Occ +
Mult(1, Educ, Occ),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations..............
Donesummary(RplusCplusRC.un)
Call:
gnm(formula = Freq ~ Educ + Occ + Cscore:Educ + Rscore:Occ +
Mult(1, Educ, Occ), family = poisson, data = freq_tab_2.3B,
tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.46856 -0.01129 -0.00160 0.02313 0.20690
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.70566 NA NA NA
Educ2 2.93231 NA NA NA
Educ3 9.84106 NA NA NA
Educ4 11.98330 NA NA NA
Occ2 -5.32506 NA NA NA
Occ3 -11.88093 NA NA NA
Occ4 -13.38551 NA NA NA
Occ5 -18.15374 NA NA NA
Educ1:Cscore 2.30655 NA NA NA
Educ2:Cscore 1.65824 NA NA NA
Educ3:Cscore 0.57607 NA NA NA
Educ4:Cscore 0.00000 NA NA NA
Occ1:Rscore -3.93278 NA NA NA
Occ2:Rscore -2.23708 NA NA NA
Occ3:Rscore -1.05781 NA NA NA
Occ4:Rscore 0.00000 NA NA NA
Occ5:Rscore 0.00000 NA NA NA
Mult(., Educ, Occ). 0.30868 NA NA NA
Mult(1, ., Occ).Educ1 0.24164 NA NA NA
Mult(1, ., Occ).Educ2 -0.05431 NA NA NA
Mult(1, ., Occ).Educ3 -0.29807 NA NA NA
Mult(1, ., Occ).Educ4 0.43140 NA NA NA
Mult(1, Educ, .).Occ1 2.28861 NA NA NA
Mult(1, Educ, .).Occ2 -2.69886 NA NA NA
Mult(1, Educ, .).Occ3 0.26160 NA NA NA
Mult(1, Educ, .).Occ4 0.21052 NA NA NA
Mult(1, Educ, .).Occ5 7.13039 NA NA NA
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 0.27843 on 2 degrees of freedom
AIC: 152.66
Number of iterations: 14pickCoef(RplusCplusRC.un, "[:]Cscore")Educ1:Cscore Educ2:Cscore Educ3:Cscore Educ4:Cscore
9 10 11 12 pickCoef(RplusCplusRC.un, "[:]Rscore")Occ1:Rscore Occ2:Rscore Occ3:Rscore Occ4:Rscore Occ5:Rscore
13 14 15 16 17 RplusCplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Rscore:Occ +
Mult(1, Educ, Occ),
constrain = c(9,12,13,14,17),
constrainTo = c(0,0,0,0,0),
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations............................
Done# 変数と係数と係数の順番を表示
data.frame(var = names(CplusRC$coefficients),
estimate = CplusRC$coefficients) |>
mutate(estimate = estimate,
number = row_number()) var estimate number
(Intercept) (Intercept) 6.132951036 1
Educ2 Educ2 -1.598655285 2
Educ3 Educ3 -0.119602932 3
Educ4 Educ4 -1.631176445 4
Occ2 Occ2 -3.281987830 5
Occ3 Occ3 -5.745938986 6
Occ4 Occ4 -3.812315688 7
Occ5 Occ5 -3.773472310 8
Occ1:Rscore Occ1:Rscore NA 9
Occ2:Rscore Occ2:Rscore 1.262590058 10
Occ3:Rscore Occ3:Rscore 1.282319390 11
Occ4:Rscore Occ4:Rscore 1.415828283 12
Occ5:Rscore Occ5:Rscore NA 13
Mult(., Educ, Occ). Mult(., Educ, Occ). 2.509132039 14
Mult(1, ., Occ).Educ1 Mult(1, ., Occ).Educ1 NA 15
Mult(1, ., Occ).Educ2 Mult(1, ., Occ).Educ2 -0.250882838 16
Mult(1, ., Occ).Educ3 Mult(1, ., Occ).Educ3 -0.280733721 17
Mult(1, ., Occ).Educ4 Mult(1, ., Occ).Educ4 NA 18
Mult(1, Educ, .).Occ1 Mult(1, Educ, .).Occ1 NA 19
Mult(1, Educ, .).Occ2 Mult(1, Educ, .).Occ2 -0.558888360 20
Mult(1, Educ, .).Occ3 Mult(1, Educ, .).Occ3 -0.126520705 21
Mult(1, Educ, .).Occ4 Mult(1, Educ, .).Occ4 -0.009237675 22
Mult(1, Educ, .).Occ5 Mult(1, Educ, .).Occ5 NA 23mu <- getContrasts(RplusCplusRC,
pickCoef(RplusCplusRC, "[.]Educ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
nu <- getContrasts(RplusCplusRC,
pickCoef(RplusCplusRC, "[.]Occ"),
ref = "mean",
scaleRef = "mean",
scaleWeights = "unit")
con <- c(0,0,0,0,0,
mu$qvframe[,1][c(1,4)],
nu$qvframe[,1][c(1,5)])
RplusCplusRC <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
Cscore:Educ +
Rscore:Occ +
Mult(1, Educ, Occ),
constrain = c(9,12,13,14,17,19,22,23,27),
constrainTo = con,
family = poisson,
data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations......................
Donemu Estimate Std. Error
Mult(1, ., Occ).Educ1 -0.76639941 0.03714637
Mult(1, ., Occ).Educ2 -0.05505913 0.08952794
Mult(1, ., Occ).Educ3 0.60073372 0.04744381
Mult(1, ., Occ).Educ4 0.22072481 0.06764890nu Estimate Std. Error
Mult(1, Educ, .).Occ1 0.83832072 0.02535129
Mult(1, Educ, .).Occ2 -0.04397713 0.08855421
Mult(1, Educ, .).Occ3 -0.11946443 0.09158773
Mult(1, Educ, .).Occ4 -0.50065982 0.06550415
Mult(1, Educ, .).Occ5 -0.17421935 0.12622465summary(RplusCplusRC)$coefficients |>
data.frame() |>
rownames_to_column("Variable") |>
dplyr::filter(grepl("Rscore|Cscore|Mult", Variable)) Variable Estimate Std..Error z.value Pr...z..
1 Educ1:Cscore 0.00000000 NA NA NA
2 Educ2:Cscore -0.29016794 0.1835938 -1.5804884 1.139951e-01
3 Educ3:Cscore -0.95452353 0.2168230 -4.4023158 1.071015e-05
4 Educ4:Cscore 0.00000000 NA NA NA
5 Occ1:Rscore 0.00000000 NA NA NA
6 Occ2:Rscore 0.00000000 NA NA NA
7 Occ3:Rscore 0.39725281 0.1673266 2.3741161 1.759102e-02
8 Occ4:Rscore 0.32684292 0.1614939 2.0238715 4.298337e-02
9 Occ5:Rscore 0.00000000 NA NA NA
10 Mult(., Educ, Occ). -2.85715993 0.5343817 -5.3466654 8.958940e-08
11 Mult(1, ., Occ).Educ1 -0.76639941 NA NA NA
12 Mult(1, ., Occ).Educ2 -0.05505913 0.1291228 -0.4264091 6.698098e-01
13 Mult(1, ., Occ).Educ3 0.60073372 0.1297703 4.6292078 3.670672e-06
14 Mult(1, ., Occ).Educ4 0.22072481 NA NA NA
15 Mult(1, Educ, .).Occ1 0.83832072 NA NA NA
16 Mult(1, Educ, .).Occ2 -0.04397713 0.1677272 -0.2621944 7.931715e-01
17 Mult(1, Educ, .).Occ3 -0.11946443 0.1842187 -0.6484923 5.166666e-01
18 Mult(1, Educ, .).Occ4 -0.50065982 0.2149854 -2.3288081 1.986923e-02
19 Mult(1, Educ, .).Occ5 -0.17421935 NA NA NA2.27 表2.7E
Wongのサポートページにあるように,gnmを用いてRC(2)の係数を推定することは難しい.ここではKateri, Maria. 2014. {}. New York: Birkhäuser. のsupportページにあるプログラムを使用して係数を求める.
\(M > 1\)のRC(M)を推定するためにはgnmのinstancesを用いる. 今はinstances = 2としており,RC(2)を用いている. なお,式(2.35)のように\(\phi\)は推定されない. これらスコアは求まるものの,直交という次元間制約が課されてない. そこで,特異値分解(SVD: singular value decomposition)によって行スコアと列スコアのそれぞれが次元間で直行するような変換を行う.
まず次元間制約が課されてない行スコアの行列(\(I\times m\))と列スコアの行列(\(J\times m\))の積を求め,モデル化での2元交互作用パラメータを求める.
RC2 <- freq_tab_2.3B |>
gnm(Freq ~ Educ + Occ +
instances(Mult(Educ, Occ), instances = 2),
family = poisson, data = _,
tolerance = 1e-12)Initialising
Running start-up iterations..
Running main iterations.......................
Donesummary(RC2)
Call:
gnm(formula = Freq ~ Educ + Occ + instances(Mult(Educ, Occ),
instances = 2), family = poisson, data = freq_tab_2.3B, tolerance = 1e-12)
Deviance Residuals:
Min 1Q Median 3Q Max
-0.631356 -0.030234 -0.004363 0.050323 0.320666
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.98690 NA NA NA
Educ2 -0.82270 NA NA NA
Educ3 1.48754 NA NA NA
Educ4 -0.08253 NA NA NA
Occ2 0.02911 NA NA NA
Occ3 -2.10701 NA NA NA
Occ4 0.26228 NA NA NA
Occ5 -3.17251 NA NA NA
Mult(., Occ, inst = 1).Educ1 -6.48058 NA NA NA
Mult(., Occ, inst = 1).Educ2 -1.57685 NA NA NA
Mult(., Occ, inst = 1).Educ3 0.59452 NA NA NA
Mult(., Occ, inst = 1).Educ4 3.79509 NA NA NA
Mult(Educ, ., inst = 1).Occ1 -0.22164 NA NA NA
Mult(Educ, ., inst = 1).Occ2 0.11057 NA NA NA
Mult(Educ, ., inst = 1).Occ3 0.15266 NA NA NA
Mult(Educ, ., inst = 1).Occ4 0.21204 NA NA NA
Mult(Educ, ., inst = 1).Occ5 -0.15669 NA NA NA
Mult(., Occ, inst = 2).Educ1 -0.39694 NA NA NA
Mult(., Occ, inst = 2).Educ2 -0.26127 NA NA NA
Mult(., Occ, inst = 2).Educ3 -0.52436 NA NA NA
Mult(., Occ, inst = 2).Educ4 0.45321 NA NA NA
Mult(Educ, ., inst = 2).Occ1 0.43735 NA NA NA
Mult(Educ, ., inst = 2).Occ2 -0.65193 NA NA NA
Mult(Educ, ., inst = 2).Occ3 0.49859 NA NA NA
Mult(Educ, ., inst = 2).Occ4 0.79497 NA NA NA
Mult(Educ, ., inst = 2).Occ5 2.99034 NA NA NA
Std. Error is NA where coefficient has been constrained or is unidentified
Residual deviance: 0.6001 on 2 degrees of freedom
AIC: 152.98
Number of iterations: 23RCmodel_coef <- function(RCmodel, row, col, m, data){
NI <- RCmodel$xlevels[[1]] |> length()
NJ <- RCmodel$xlevels[[2]] |> length()
iflag <- 0
y <- length(RCmodel$y)
X <- gl(NI,NJ,length = y)
Y <- gl(NJ,1,length = y)
IX <- pickCoef(RCmodel,
paste0("[.]",deparse(substitute(row))))
IY <- pickCoef(RCmodel,
paste0("[.]",deparse(substitute(col))))
X <- RCmodel$coefficients[IX]
Y <- RCmodel$coefficients[IY]
mu0 <- matrix(X,nrow = NI,ncol = m)
nu0 <- matrix(Y,nrow = NJ,ncol = m)
mu <- mu0
nu <- nu0
A <- mu %*% t(nu) # [NI, M] [M. NJ]
R1 <- diag(1,NI)
C1 <- diag(1,NJ)
Rone <- matrix(rep(1,NI^2),nrow = NI)
Cone <- matrix(rep(1,NJ^2),nrow = NJ)
rowP <- c(rep(1,NI))
colP <- c(rep(1,NJ));
data <- RC2$model
list(y,X,Y,IX,IY,data)
if (iflag == 1) {
rowP <- with(data, tapply(freq,row,sum)/sum(freq))
colP <- with(data, tapply(freq,col,sum)/sum(freq))}
DR <- diag(rowP^(-1/2),NI)
DC <- diag(colP^(-1/2),NJ)
RWsqr <- diag(rowP^(1/2),NI)
CWsqr <- diag(colP^(1/2),NJ)
RW <- RWsqr^2
CW <- CWsqr^2
L <- (R1 - (Rone %*% RW)/sum(RW)) %*% A %*% t(C1 - (Cone %*% CW)/sum(CW))
phiv <- svd(RWsqr %*% L %*% CWsqr)$d[1:m]
mu <- svd(RWsqr %*% L %*% CWsqr)$u[,1:m]
nu <- svd(RWsqr %*% L %*% CWsqr)$v[,1:m]
mu <- DR %*% mu
nu <- DC %*% nu
phi <- diag(phiv, m)
L2 <- RCmodel$deviance
df <- RCmodel$df.residual
p.value <- 1 - pchisq(L2,df)
fit.freq <- predict(RCmodel,
type = "response",
se.fit = TRUE)
print(list(model = RCmodel,
L2 = L2,
df = df,
p.value = p.value,
obs_freq = summary(RC2)$y,
fit.freq = fit.freq,
phi = phi,
mu = mu,
nu = nu,
cor(mu) |> round(3),
cor(nu) |> round(3)))
}
RCmodel_coef(RC2, row = Educ, col = Occ, m = 2)$model
Call:
gnm(formula = Freq ~ Educ + Occ + instances(Mult(Educ, Occ),
instances = 2), family = poisson, data = freq_tab_2.3B, tolerance = 1e-12)
Coefficients:
(Intercept) Educ2
4.98690 -0.82270
Educ3 Educ4
1.48754 -0.08253
Occ2 Occ3
0.02911 -2.10701
Occ4 Occ5
0.26228 -3.17251
Mult(., Occ, inst = 1).Educ1 Mult(., Occ, inst = 1).Educ2
-6.48058 -1.57685
Mult(., Occ, inst = 1).Educ3 Mult(., Occ, inst = 1).Educ4
0.59452 3.79509
Mult(Educ, ., inst = 1).Occ1 Mult(Educ, ., inst = 1).Occ2
-0.22164 0.11057
Mult(Educ, ., inst = 1).Occ3 Mult(Educ, ., inst = 1).Occ4
0.15266 0.21204
Mult(Educ, ., inst = 1).Occ5 Mult(., Occ, inst = 2).Educ1
-0.15669 -0.39694
Mult(., Occ, inst = 2).Educ2 Mult(., Occ, inst = 2).Educ3
-0.26127 -0.52436
Mult(., Occ, inst = 2).Educ4 Mult(Educ, ., inst = 2).Occ1
0.45321 0.43735
Mult(Educ, ., inst = 2).Occ2 Mult(Educ, ., inst = 2).Occ3
-0.65193 0.49859
Mult(Educ, ., inst = 2).Occ4 Mult(Educ, ., inst = 2).Occ5
0.79497 2.99034
Deviance: 0.6001022
Pearson chi-squared: 0.5746549
Residual df: 2
$L2
[1] 0.6001022
$df
[1] 2
$p.value
[1] 0.7407804
$obs_freq
NULL
$fit.freq
$fit.freq$fit
1 2 3 4 5 6
517.836063 95.414391 5.433736 35.145848 5.169961 81.405000
7 8 9 10 11 12
65.976261 5.398934 48.639687 1.580117 451.846566 1003.387842
13 14 15 16 17 18
66.470016 630.136504 5.159072 70.912370 157.221505 36.697314
19 20
562.077961 12.090850
$fit.freq$se.fit
1 2 3 4 5 6 7 8
22.748933 9.732333 2.174395 5.860792 2.230227 8.912865 7.856714 1.044826
9 10 11 12 13 14 15 16
6.616317 0.619348 21.250045 31.666672 8.114913 25.088611 2.233235 8.415482
17 18 19 20
12.530867 6.041164 23.703381 3.469126
$fit.freq$residual.scale
[1] 1
$phi
[,1] [,2]
[1,] 2.600861 0.000000
[2,] 0.000000 1.521971
$mu
[,1] [,2]
[1,] 0.74345129 0.27619989
[2,] 0.08846472 -0.06103682
[3,] -0.19984223 -0.77722344
[4,] -0.63207378 0.56206037
$nu
[,1] [,2]
[1,] 0.76509960 -0.137064850
[2,] 0.01966104 -0.548959995
[3,] -0.32245067 -0.119769392
[4,] -0.55005650 -0.009934123
[5,] 0.08774653 0.815728360
[[10]]
[,1] [,2]
[1,] 1 0
[2,] 0 1
[[11]]
[,1] [,2]
[1,] 1 0
[2,] 0 1logmultパッケージのrcによってRC(2)を推定する.まずはanoasで連関分析を行う.表2.6Aと同じ結果になっていることを確認する.正規化だけではなく,次元間制約が課されており,表2.7の結果と一致する.
anoas(tab_2.3B)Fitting independence model...
Fitting model with 1 dimension...
Initialising
Running start-up iterations..
Running main iterations.........................................................
........
Done
Fitting model with 2 dimensions...
Initialising
Running start-up iterations..
Running main iterations.........
Done
Fitting model with 3 dimensions...
Initialising
Running start-up iterations..
Running main iterations...
Done Res. Df Res. Dev Dev./Indep. (%) Dissim. (%)
Indep. 12 1373.17576565224545 100.000000000000000 23.8615752953
RC(1) 6 125.05974855014664 9.107337289101110 6.4360390988
RC(2) 2 0.60010223526822 0.043701778772885 0.0935165803
RC(3) 0 0.00000000000009 0.000000000000006 0.0000000007
BIC AIC Dev. Df
Indep. 1274.08091533065726 1349.17576565224545 NA NA
RC(1) 75.51232338935259 113.05974855014664 -1248.1 -6
RC(2) -15.91570615166313 -3.39989776473178 -124.5 -4
RC(3) 0.00000000000009 0.00000000000009 -0.6 -2RC2 <- rc(tab_2.3B,
nd = 2,
weighting = "none",
se = "bootstrap",
nreplicates = 1000,
ncpus = getOption("boot.ncpus"))Initialising
Running start-up iterations..
Running main iterations.......
Done
Computing bootstrap standard errors...
.summary(RC2)Call:
rc(tab = tab_2.3B, nd = 2, weighting = "none", se = "bootstrap",
nreplicates = 1000, ncpus = getOption("boot.ncpus"))
Deviance Residuals:
Columns
Rows A B C D E
A 0.00720 -0.04245 0.23888 -0.02462 -0.07516
B -0.04493 0.12571 -0.63136 0.05160 0.32067
C 0.00722 -0.01224 0.06492 -0.00544 -0.07040
D 0.01040 -0.01767 0.04990 -0.00329 -0.02616
Association coefficients:
Normalized Adjusted Std. error Pr(>|z|)
Dim1 2.6008615 NA 0.1873 < 2.2e-16 ***
Dim2 1.5219709 NA 0.5272 0.003890 **
Dim1:RowsA 0.7434513 1.1989778 0.0188 < 2.2e-16 ***
Dim1:RowsB 0.0884647 0.1426687 0.0410 0.031124 *
Dim1:RowsC -0.1998422 -0.3222893 0.0226 < 2.2e-16 ***
Dim1:RowsD -0.6320738 -1.0193572 0.0185 < 2.2e-16 ***
Dim2:RowsA 0.2761999 0.3407428 0.0903 0.002220 **
Dim2:RowsB -0.0610368 -0.0753000 0.1571 0.697718
Dim2:RowsC -0.7772234 -0.9588465 0.0637 < 2.2e-16 ***
Dim2:RowsD 0.5620604 0.6934037 0.0696 6.804e-16 ***
Dim1:ColumnsA 0.7650996 1.2338904 0.0399 < 2.2e-16 ***
Dim1:ColumnsB 0.0196610 0.0317077 0.0404 0.626275
Dim1:ColumnsC -0.3224507 -0.5200222 0.0991 0.001142 **
Dim1:ColumnsD -0.5500565 -0.8870864 0.0688 1.277e-15 ***
Dim1:ColumnsE 0.0877465 0.1415105 0.0992 0.376475
Dim2:ColumnsA -0.1370648 -0.1690944 0.0473 0.003746 **
Dim2:ColumnsB -0.5489600 -0.6772420 0.0805 9.003e-12 ***
Dim2:ColumnsC -0.1197694 -0.1477573 0.0935 0.200113
Dim2:ColumnsD -0.0099341 -0.0122555 0.0708 0.888363
Dim2:ColumnsE 0.8157284 1.0063493 0.0557 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Normalization weights: none
Deviance: 0.6001022
Pearson chi-squared: 0.5746549
Dissimilarity index: 0.09351658%
Residual df: 2
BIC: -15.91571
AIC: -3.399898RC2 |>
summary() |>
pluck(coefficients) |>
data.frame() |>
rownames_to_column(var = "Parameter") |>
arrange(Parameter) Parameter Normalized Adjusted Std..error Pr...z..
1 Dim1 2.600861491 NA 0.18733724 7.996127e-44
2 Dim1:ColumnsA 0.765099599 1.23389040 0.03987968 4.920472e-82
3 Dim1:ColumnsB 0.019661041 0.03170773 0.04037365 6.262746e-01
4 Dim1:ColumnsC -0.322450671 -0.52002222 0.09912245 1.141718e-03
5 Dim1:ColumnsD -0.550056503 -0.88708639 0.06878444 1.276783e-15
6 Dim1:ColumnsE 0.087746534 0.14151047 0.09921477 3.764749e-01
7 Dim1:RowsA 0.743451285 1.19897776 0.01883771 0.000000e+00
8 Dim1:RowsB 0.088464723 0.14266871 0.04104172 3.112406e-02
9 Dim1:RowsC -0.199842229 -0.32228929 0.02258981 9.025530e-19
10 Dim1:RowsD -0.632073780 -1.01935718 0.01851006 1.452479e-255
11 Dim2 1.521970932 NA 0.52719756 3.890478e-03
12 Dim2:ColumnsA -0.137064849 -0.16909442 0.04728359 3.746148e-03
13 Dim2:ColumnsB -0.548959996 -0.67724199 0.08047383 9.003428e-12
14 Dim2:ColumnsC -0.119769391 -0.14775733 0.09347999 2.001128e-01
15 Dim2:ColumnsD -0.009934123 -0.01225555 0.07076807 8.883631e-01
16 Dim2:ColumnsE 0.815728359 1.00634928 0.05570139 1.457086e-48
17 Dim2:RowsA 0.276199888 0.34074279 0.09028681 2.219741e-03
18 Dim2:RowsB -0.061036818 -0.07530002 0.15714808 6.977177e-01
19 Dim2:RowsC -0.777223438 -0.95884646 0.06373209 3.298285e-34
20 Dim2:RowsD 0.562060367 0.69340368 0.06961379 6.804270e-16# getS3method("assoc","rc")